
Welcome to the DCG 201 Guides for Hacker Summer Camp 2023! This is part of a series where we are going to cover all the various hacker conventions and shenanigans both In-Person & Digital! This year in 2023 somehow bigger than it was in 2022 and thus we will have a total of 15 guides spanning 3 Months of Hacker Insanity!
As more blog posts are uploaded, you will be able to jump through the guide via these links:
HACKER SUMMER CAMP 2023 — Part One: Surviving Las Vegas & Virtually Anywhere
HACKER SUMMER CAMP 2023 — Part Two: Capture The Flags & Hackathons
HACKER SUMMER CAMP 2023 — Part Three: SummerC0n
HACKER SUMMER CAMP 2023 — Part Four: Zero Gravity by RingZero
HACKER SUMMER CAMP 2023 — Part Five: The Diana Initiative
HACKER SUMMER CAMP 2023 — Part Six: BSides Las Vegas
HACKER SUMMER CAMP 2023 — Part Seven: Black Hat USA
HACKER SUMMER CAMP 2023 — Part Eight: SquadCon by Black Girls Hack
HACKER SUMMER CAMP 2023 — Part Nine: DEFCON 31
HACKER SUMMER CAMP 2023 — Part Ten: USENIX + SOUPS
HACKER SUMMER CAMP 2023 — Part Eleven: Chaos Computer Camp
HACKER SUMMER CAMP 2023 — Part Twelve: Wikimania 2023
HACKER SUMMER CAMP 2023 — Part Thirteen: HackCon XI
HACKER SUMMER CAMP 2023 — Part Fourteen: Blue Team Con
HACKER SUMMER CAMP 2023 — Part Fifteen: Hack Red Con
HACKER SUMMER CAMP 2023 — Part Sixteen: SIGS, EVENTS & PARTIES

USENIX 32ND SECURITY SYMPOSIUM + Nineteenth Symposium on Usable Privacy and Security
Date: Wednesday, August 9th (12:30 PM EST) — Friday, August 11th (8:00 PM EST)
Location: Anaheim Marriott (700 W Convention Way Anaheim, CA 92802)
Website:
USENIX — https://www.usenix.org/conference/usenixsecurity23
SOUPS — https://www.usenix.org/conference/soups2022
Platform(s): Unknown Custom Platform
Schedule:
USENIX — https://www.usenix.org/conference/usenixsecurity23/technical-sessions
SOUPS — https://www.usenix.org/conference/soups2023/technical-sessions
Live Streams:
UNKNOWN
Chat:
UNKNOWN
Accessibility: USENIX Security ’22 Technical Sessions will increase to $1200 ($600 for Students) In-Person. SOUPS 2022 will cost $700 ($400 for Students) with $150 to attend Full Day Workshops and $75 to attend Half Day Workshops. Talks after their formal presentation including white paper, slides and video are archived and are posted online for FREE.
Tickets:
USENIX — https://www.usenix.org/conference/268491/registration/form
SOUPS — https://www.usenix.org/conference/278983/registration/form
Code Of Conduct: https://www.usenix.org/conferences/coc

The USENIX Association is a 501(c)(3) nonprofit organization, dedicated to supporting the advanced computing systems communities and furthering the reach of innovative research. It was founded in 1975 under the name “Unix Users Group,” focusing primarily on the study and development of Unix and similar systems. It has since grown into a respected organization among practitioners, developers, and researchers of computer operating systems more generally. Since its founding, it has published a technical journal entitled ;login:.
USENIX’S MISSION:
- Foster technical excellence and innovation
- Support and disseminate research with a practical bias
- Provide a neutral forum for discussion of technical issues
- Encourage computing outreach into the community at large
The 32nd USENIX Security Symposium will take place on August 9–11, 2023, at the Anaheim Marriott in Anaheim, CA, USA. The USENIX Security Symposium brings together researchers, practitioners, system administrators, system programmers, and others interested in the latest advances in the security and privacy of computer systems and networks.
A decently priced option for the technically minded, sponsored by the EFF, NoStarch Press, FreeBSD Foundation (and others) while also organized by a long standing organization.

The Nineteenth Symposium on Usable Privacy and Security (SOUPS 2023) will take place at the Anaheim Marriott in Anaheim, CA, USA, on August 6–8, 2023. SOUPS brings together an interdisciplinary group of researchers and practitioners in human-computer interaction, security, and privacy.
A long standing institution, this convention is focused on the Security & Privacy side of hacking viewed through an academic and research focused-lens. If you like to read white papers on security research these two back-to-back conventions are for you!
WHERE IS ANYTHING IN THIS MUTANT CITY BECAUSE THE F%$KING TALKING MOUSE WON’T EXPLAIN ANYTHING!?
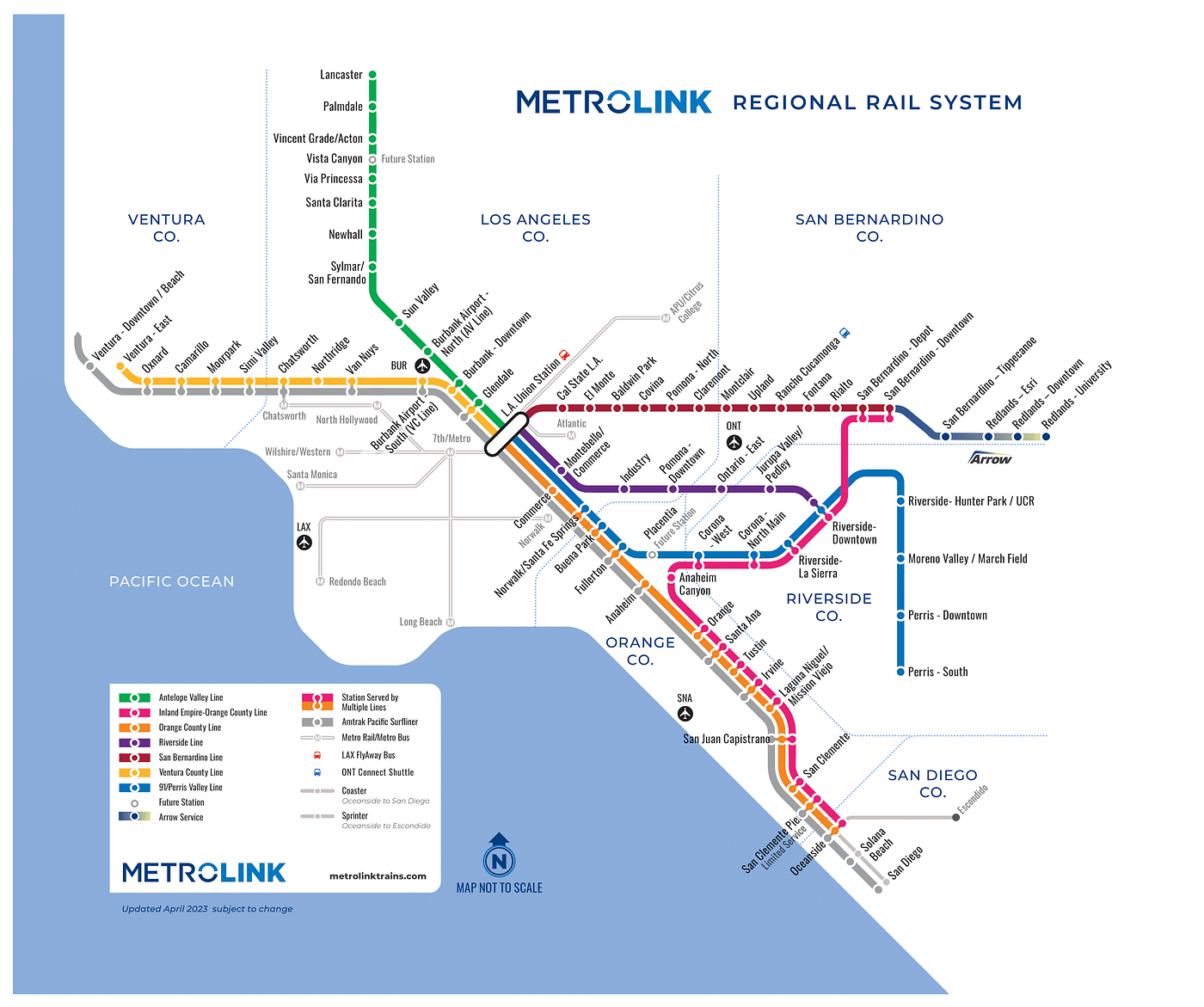
All About Metrolink Fares
Metrolink fares are based on where you start and end your trip using the shortest driving distance. For example, your trip from Fullerton to San Juan Capistrano would cost more than your trip from Fullerton to Irvine. To determine your exact fare, use the handy fare calculator.
Metrolink offers many different types of tickets. For example, seniors and persons with disabilities receive 50 percent off one-way and round-trip tickets and 25 percent off monthly and 7-day passes. Metrolink is also family-friendly, with children ages 5 and under riding FREE with each fare-paying adult (limit three children per adult). Before heading out on your train trip, it’s always a good idea to check the Ticket Types section to see if you are eligible for a discount.
Extra Benefits
With your Metrolink ticket, most connections to local transit are free. For example, most Metrolink tickets are also EZ transit passes, good for all-day travel in Los Angeles County on participating bus and Metro Rail lines. Click here to learn more.
How to Choose the Right Ticket
If you’re traveling your destination and won’t be returning, the one-way ticket is your best option. If you’re returning by train or plan to ride several times, you can save by buying a round-trip ticket or 7-Day Pass. And if you will be riding Metrolink regularly, then the monthly pass is your ticket to great savings.
How to Purchase Your Ticket
Purchase your tickets and monthly passes from the self-service ticket vending machines (TVMs) found at all the Metrolink stations or through the Metrolink App. You can also purchase your ticket at Metrolink ticket windows located in the east and west portals of the Los Angeles Union Station. Tickets are not sold on board.
Non-refundable and non-replaceable, Metrolink tickets are sold at ticket-vending machines on station platforms.
One-Way Ticket
Valid for a single one-way trip between the origin and destination stations. One-way tickets are valid for three hours from time of purchase. One-way mobile tickets expire at 3 am following the date of purchasing. Best for those who travel infrequently and plan to stay at their destination for more than one day.
Round-Trip Ticket
Valid for a round-trip on the same day between the origin and destination stations. Travel must begin within three hours from time of purchase and end that same day. Round-trip mobile tickets expire at 3 am following the date of purchase. Ideal for infrequent travelers who complete their trip in one day.
Advance Purchase Ticket
One-way or round-trip tickets can be purchased up to one year in advance. Select the advance purchase option and choose your travel date and ticket type. Unlike a same-day travel ticket, an advance purchase ticket will not include a printed expiration time. Use it any time on the day you chose to travel.
7-Day Pass
Good for unlimited trips for seven consecutive days starting on the day of purchase between a set origin and destination, the 7-Day Pass is priced at seven one-way trips. Discounts apply for senior/disabled/Medicare (25 percent off) and students (10 percent off). It may not be purchased in advance.
5-Day Flex Pass
The 5-Day Flex Pass is available only on the Metrolink Mobile App. To purchase, riders choose their origin and destination stations, then select 5-Day Flex Pass from the ticket menu. Once the pass is purchased, riders will find five one-day passes in their Mobile App ticket wallet. On the day of travel, the rider simply activates one of the one-day passes before boarding; the activated one-day pass will expire at the end of the day. Each 5-Day Flex Pass is valid for 30 days, allowing riders the flexibility to choose when to use their individual tickets to travel.
The 5-Day Flex Pass is valid for a 10 percent discount compared to one-way and round-trip ticket prices that can be used in conjunction with other reduced ticket types, such as student or senior passes.
10-Day Flex Pass
The 10-Day Flex Pass is a new fare type that is perfect if for hybrid or flexible commuting or for less frequent travel. With the click of a button, you get the flexibility of 10 one-day passes to use when you need to travel within 60 days. The 10-Day Flex pass offers 10% savings on the cost of 10 round-trip tickets. Just buy the pass exclusively on the Metrolink Mobile App before your trip; 10 one-day tickets are saved in your ticket wallet; simply activate one ticket each day you travel before you board the train.
$10 Weekend Day Pass
Adult:
The Metrolink Weekend Day Pass allows purchasers to ride anytime, anywhere system-wide on Saturday or Sunday for only $10. This pass includes free transfers to connecting rail or bus, except Amtrak. Metrolink monthly pass holders ride free on weekends systemwide. The $10 Weekend Day Pass is available for purchase on Saturday or Sunday on the Metrolink Mobile App or at ticket vending machines at any Metrolink station with weekend service and can be purchased by selecting “Weekend Day Pass” on the home screen.
Child:
On weekends, three children 17 and under can ride free when accompanied by a fare-paying adult.
$15 Summer Day Pass
The $15 Summer Day Pass is a weekday ticket perfect for summer travel Monday through Friday throughout Metrolink’s service area. The ticket provides unlimited rides on one weekday of travel system-wide at a flat $15 price no matter where you go. The new $15 Summer Day Pass is available from Tuesday, May 30 through Friday, September 1, 2023. The $15 Summer Day Pass is available on the Metrolink Mobile App and at station ticket machines. No advance purchase — must be used on date of purchase.
Monthly Pass
Valid for unlimited travel between the origin and destination station during the calendar month printed on the pass. For convenience, monthly passes are sold from the 25th of the current month to the 14th of the new month. As a special benefit and at no additional charge, monthly pass holders can ride any Metrolink train from Friday 7 p.m. through 11:59 p.m. Sunday all weekend long, anywhere in the Metrolink system. Also at no additional charge, monthly pass holders can ride both Metrolink and Amtrak Pacific Surfliner trains between the stations paired on the ticket as part of the Rail 2 Rail® program.
Low Income Fare
California Electronic Benefit Transfer (EBT) cardholders qualify for 50% off Metrolink ticket or pass. Travel to school, work and anywhere else across SoCal Metrolink’s service area. Riders with an EBT card must purchase a paper ticket from a Metrolink ticket vending machine. For more information, visit https://metrolinktrains.com/lowincomefare or for Spanish https://metrolinktrains.com/programa-de-descuento-de-tarifas/.
Metrolink and Amtrak Transfers
Only OCTA buses that directly connect with Metrolink trains at or near rail stations will honor Metrolink tickets and passes. Only OCTA routes 1, 25, 26, 29, 38, 43, 47/A, 50, 53, 54, 56, 57, 59, 70, 71, 83, 85, 86, 90, 91, 123, 143, 153, 453, 463, 472, 473, 480, 543, 553, 560 accept valid Metrolink tickets as full fare for travel to and from stations. A valid Metrolink ticket must be shown each time you board the bus; passengers must show a valid Metrolink pass or ticket, swipe a valid OCTA pass *, or pay the cash fare to board. Amtrak tickets cannot be used as transfers.
- Additional fare may be required for express routes.
Android App: https://play.google.com/store/apps/details?id=com.justride.metrolink
iOS App: https://itunes.apple.com/us/app/metrolink/id1083843914?mt=8
Ticket Vending Machines
Every Metrolink station has a ticket vending machine (TVM) allowing you to purchase your ticket or pass right on the spot. New ticket machines accept cash, credit and debit cards, Corporate Quick Cards and promotional codes for payment. Later this year, Apple Pay, Samsung Pay, Google Pay, and transit vouchers can be used to purchase tickets.
To begin your purchase, tap the screen to get started! Select “Buy Tickets” when prompted. You may also select to purchase a One Way Ticket, use your Corporate Quick Card or promotional code, or you can purchase a Special Event Ticket on this initial screen. The TVM has automatically selected your origin station.
Select type of ticket:
TVMs offer a variety of ticket types. The ticket best suited for you depends on how often you plan to ride Metrolink. Visit above section to view ticket options.
Select destination:
Choose the station you are traveling to. Verify your origin and destination stations when prompted. Tap “Next”.
Insert your payment when prompted:
Metrolink TVM’s accept cash, credit and debit cards, Corporate Quick Cards and promotional codes. Use the pin pad to complete your purchase if you paid with a card.
Take your ticket:
Now you’re ready to ride!
Pass By Mail
You can purchase your monthly pass from the convenience of home. Just download the Pass By Mail form and put in the mail. Remember, the form must be received before the 15th of the month to receive your pass by the 1st of the new month.
ORANGE COUNTY “OC” BUS
BIKING IN ORANGE COUNTY
Extend Your Bike Trip by Bus
If you are traveling a long distance, you can ride your bicycle to a bus stop and take a bus to your destination. All OCTA buses are equipped with bicycle racks, located at the front of the vehicle that can carry two bicycles at a time. Note that the driver is not required to help you load or unload your bike.
OCTA buses can hold most bikes that meet these specifications:
- Wheel Size: 20–29 inches in diameter
- Wheelbase: 44 inches maximum axle to axle
- Tire Width: no more than 2.35 inches
Go Further with Metrolink and Bike Cars
Every Metrolink can hold up to 3 bikes, and the special Bike Cars can hold up to 18 bikes. With 12 Metrolink stations located through Orange County, it’s a convenient way to extend your trip or shorten your bicycle commute — all you have to do is grab your bike and go!
Check Metrolink’s website for updated bike information. For weekend trains, take advantage of the $10 Weekend Day Pass for unlimited travel on either Saturday or Sunday.
Bike Lockers
Bike lockers throughout Orange County provide a safe place to store your bike. Bike lockers are conveniently located at Metrolink stations so bicyclists can protect their rides from weather, vandalism and theft in a fully enclosed unit.
Bike lockers can be reserved through each of the city agencies listed below. Some bike lockers require deposits and/or memberships. See below for bike locker locations and additional information.
- Anaheim
2150 E. Katella Ave., Anaheim, CA 92806 (at Angel Stadium)
Bike Lockers: 9 - Anaheim ARTIC
2626 East Katella Avenue, Anaheim, CA 92806
Bike Lockers: 12 - Anaheim Canyon
1039 N. Pacificenter Drive, Ahaheim, CA 92806
Bike Lockers: 16
Reserve at 714–765–5277
The OC Loop
The Orange County (OC) Loop is a vision for 66 miles of seamless connections and an opportunity for people to bike, walk, and connect to some of California’s most scenic beaches and inland reaches. About 88% of the OC Loop is already in place and is used by thousands of people. Currently, nearly 58 miles use existing off-street trails along the San Gabriel River, Coyote Creek, Santa Ana River, and the Coastal/Beach Trail.
Anaheim Regional Transportation
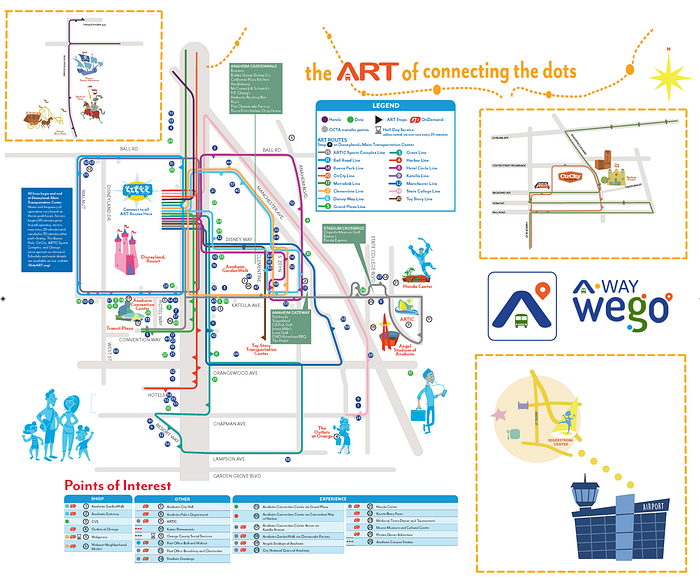
Android App: https://play.google.com/store/apps/details?id=org.rideart.awaywego
iOS App: https://apps.apple.com/us/app/a-way-wego/id1589114302
Anaheim Regional Transportation (ART) is a public transportation system operating within The Anaheim Resort™ District and surrounding areas. Every year, over 9 million residents, visitors and employees use ART to connect with local destinations, theme parks, sport venues, shopping centers, hotels, restaurants and ARTIC regional transportation center. ART is a hop-on/hop-off service that connects convenience with fun.
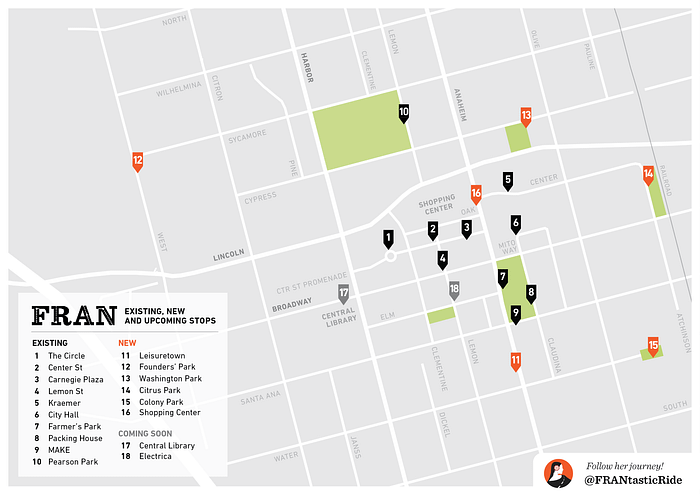
What is FRAN?
The City of Anaheim, in partnership with Anaheim Transportation Network (ATN), now offers Free Rides Around the Neighborhood– FRAN, where convenience and unique experiences meet.
FRAN is an on-demand micro-transit system of sustainable electric vehicles currently serving Anaheim’s downtown area known as “Center City”.
Her first day on the job was January 24th 2019. FRAN has truly been a game changer for locals and visitors alike.
What makes FRAN different from other services?
FRAN microtransit is completely free to use! This service is a joint venture between ART and the city of Anaheim, funded by grants and local property assessments. Rides can be requested via the A-Way WeGo app or by hailing in-person.
“[FRAN] integrates with pedestrian, auto and bus mobility in Center City, which has developed into a constellation of booming retail, restaurant, residential, office and entertainment destinations.”
PHYSICAL LOCATION RECON

Anaheim Marriott
700 W Convention Way
Anaheim, CA 92802
USA
+1 714.750.8000
Special Attendee Room Rate
USENIX has negotiated a special conference attendee room rate of US$229 plus tax for single/double occupancy, including in-room wireless internet. To receive this rate, book your room online or call the hotel and mention USENIX or Security ‘23.
The group rate is available until Monday, July 17, 2023, or until the block sells out, whichever occurs first. After this date, contact the hotel directly to inquire about room availability.
Room Sharing
USENIX utilizes Google Groups to facilitate room sharing. You can sign up for free to find attendees with whom you can share a hotel room, taxi, etc. Please include “USENIX Security ‘23” in the subject line when posting a new room share request.
USENIX Conference Policies
We encourage you to learn more about USENIX’s values and they put them into practice at our conferences.
Refunds and Cancellations
They are unable to offer refunds, cancellations, or substitutions for any registrations for this event. Please contact the Conference Department at conference@usenix.org with any questions.
Questions?
Send direct queries via email:
Registration: conference@usenix.org
Membership: membership@usenix.org
Sponsorship: sponsorship@usenix.org
Student Grants: students@usenix.org
Proceedings Papers: production@usenix.org

PUBLISHED PAPERS
USENEX Papers and Proceedings
The full Proceedings published by USENIX for the symposium are available for download below. Individual papers can also be downloaded from their respective presentation pages. Copyright to the individual works is retained by the author[s].
USENIX Security ’23 Activities
To enhance your symposium experience, several attendee events are planned throughout the week. They are open to all USENIX Security ’23 attendees. Check back here for the latest additions to the activities schedule.

Symposium Reception and Presentation of the USENIX Lifetime Achievement Award
Wednesday, 6:00 pm–7:30 pm
Mingle with fellow attendees at the USENIX Security ’23 Reception, featuring dinner, drinks, and the chance to connect with other attendees, speakers, and symposium organizers.

Lightning Talks
Wednesday, 7:30 pm–8:30 pm
We will host a Lightning Talks session (also previously known as Work-in-Progress/Rump session) on the evening of Wednesday, August 9, 2023. This is intended as an informal session of short and engaging presentations on recent unpublished results, work in progress, or other topics of interest to USENIX Security attendees. As in the past, talks do not always need to be serious and funny talks are encouraged! For full consideration, submit your lightning talk via the lightning talk submission form, through Wednesday, July 26, 2023, 11:59 pm AoE. You can continue submitting talks via the submission form until Monday, August 7, 2023, 12:00 pm PDT. However, due to time, there is no guarantee of full consideration after the initial deadline.

Birds-of-a-Feather Sessions (BoFs)
Registered attendees may schedule Birds-of-a-Feather sessions (BoFs) and reserve meeting rooms for them via the USENIX Security Slack space. The attendee guide, which will be sent to registered attendees shortly before the event, contains more details for joining the Slack space and scheduling a BoF. Each room will be set with a projector and screen, in one-hour increments.
Wednesday, August 9
- Orange County Ballroom 1, 8:30 pm–10:30 pm
- Orange County Ballroom 2, 8:30 pm–10:30 pm
- Orange County Ballroom 3, 8:30 pm–10:30 pm
- Orange County Ballroom 4, 9:30 pm–10:30 pm
Thursday, August 10
- Orange County Ballroom 1, 8:30 pm–10:30 pm
- Orange County Ballroom 2, 9:30 pm–10:30 pm
- Orange County Ballroom 3, 7:30 pm–10:30 pm
- Orange County Ballroom 4, 7:30 pm–10:30 pm
SOUPS 2023 Activities
To enhance your symposium experience, several attendee events are planned throughout the week. They are open to all SOUPS 2023 attendees. Check back here for the latest additions to the activities schedule.
Monday Luncheon and Mentoring Tables
Monday, 12:30 pm–1:45 pm
See the Mentoring Program page for more information.
SOUPS 2023 Poster Session and Reception
Monday, 5:30 pm–6:45 pm
Check out the cool new ideas and the latest preliminary research on display at the SOUPS Poster Session and Reception. The list of accepted posters will be available soon.
Tuesday Luncheon and Speed Mentoring Tables
Tuesday, 12:15 pm–1:30 pm
See the Mentoring Program page for more information.

About GREPSEC
GREPSEC VI will be held on Tuesday, August 8, 2023.
GREPSEC is a workshop for PhD students in computer security and privacy, focusing on underrepresented populations, including women, non-binary, and gender minorities; Black, Hispanic/Latino/Latina, Native American and Indigenous students; and LGBTQ+ students.
The GREPSEC program will be available soon and include research talks, mentoring, and social/networking sessions. The workshop will be a relaxed event, focused on creating and fostering lasting connections within the computer security and privacy community. The program will provide ample time to engage informally with speakers about research opportunities and career paths. Speakers will be invited based on accomplishments in research as well as their ability to mentor students from diverse backgrounds.
Attending GREPSEC VI
Apply here. Applications are due on May 24, 2023.
There is NO REGISTRATION FEE for attendees who are accepted to the workshop. Students from US-based institutions who are accepted to the GREPSEC workshop will be eligible for travel grants; funding may also be available for a few international students.
GREPSEC is scheduled for the Tuesday, August 8, immediately preceding the 32nd USENIX Security Symposium (USENIX Security ’23) and taking place concurrently with the Nineteenth Symposium on Usable Privacy and Security (SOUPS 2023), to encourage workshop attendees to network with attendees of both symposia. All GREPSEC attendees are also encouraged to also apply for a grant to attend USENIX Security ’23. Grants are competitive, and cover partial hotel and registration. Applications will go live when USENIX Security ’23 registration opens later this year.
Space is limited and an application is required of all potential attendees. Applicants should be a graduate or postdoctoral student, with strong preference for those actively doing research (toward eventual publication) in security and privacy.
Workshop Organizers
General Chair
Michelle Mazurek, University of Maryland
Program Co-Chairs
Christina Garman, Purdue University
Yuan Tian, UCLA
Steering Committee
Terry Benzel, University of Southern California’s Information Sciences Institute
Susan Landau, Tufts University
Hilarie Orman, Purple Streak
GREPSEC VI Workshop Program
Tuesday, August 8
8:30 am–9:00 am
Breakfast/Coffee
9:00 am–9:15 am
Welcome Reception
9:15 am–9:45 am
Talk 1
Kevin Butler, University of Florida
9:45 am–10:15 am
Talk 1 Q&A
10:15 am–10:45 am
Break
10:45 am–11:30 am
Breakout Session 1
11:30 am–12:00 pm
Talk 2
Roya Ensafi, University of Michigan
12:00 pm–12:30 pm
Talk 2 Q&A
12:30 pm–2:00 pm
Lunch
2:00 pm–2:30 pm
Talk 3
Limin Jia, Carnegie Mellon University
2:30 pm–3:00 pm
Talk 3 Q&A
3:00 pm–3:45 pm
Breakout Session 2
3:45 pm–4:15 pm
Break
4:15 pm–4:45 pm
Talk 4
Franzi Roesner, University of Washington
4:45 pm–5:15 pm
Talk 4 Q&A
5:15 pm–5:30 pm
Concluding Remarks and Wrap Up
5:30 pm–6:00 pm
End of Day Break
6:00 pm–7:00 pm
Speed Mentoring with Appetizers

DCG 201 TALK HIGHLIGHTS FOR USENIX 32 & SOUPS 2023
This is the section where we have comb through the entire list of talks on both days and list our highlights for the talks that stand out to us. Note that this does not invalidate any talks we didn’t list, in fact, we highly recommend you take a look at the full USENIX & SOUPS convention schedule beforehand and make up your own talk highlight lists. These are just the talks that for us had something stand out, either by being informative, unique or bizarre. (Sometimes, all three!)
SOUPS 2023 Technical Sessions
Monday, August 7
9:00 am–9:15 am
Opening Remarks and Awards
General Chairs: Patrick Gage Kelley, Google, and Apu Kapadia, Indiana University Bloomington
9:15 am–10:30 am
An Investigation of Teenager Experiences in Social Virtual Reality from Teenagers’, Parents’, and Bystanders’ Perspectives
Elmira Deldari, University of Maryland, Baltimore County; Diana Freed, Cornell Tech; Julio Poveda, University of Maryland; Yaxing Yao, University of Maryland, Baltimore County
The recent rise of social virtual reality (VR) platforms has introduced new technology characteristics and user experiences, which may lead to new forms of online harassment, particularly among teenagers (individuals aged 13–17). In this paper, we took a multi-stakeholder approach and investigate teenagers’ experiences and safety threats in social VR from three perspectives (teenagers, parents, and bystanders) to cover complementary perspectives. Through an interview study with 24 participants (8 teenagers, 7 parents, and 9 bystanders), we found several safety threats that teenagers may face, such as virtual grooming, ability-based discrimination, unforeseeable threats in privacy rooms, etc. We highlight new forms of harassment in the social VR context, such as erotic role-play and abuse through phantom sense, as well as the discrepancies among teenagers, parents, and bystanders regarding their perceptions of such threats. We draw design implications to better support safer social VR environments for teenagers.
Fight Fire with Fire: Hacktivists’ Take on Social Media Misinformation
Filipo Sharevski and Benjamin Kessell, DePaul University
In this study, we interviewed 22 prominent hacktivists to learn their take on the increased proliferation of misinformation on social media. We found that none of them welcomes the nefarious appropriation of trolling and memes for the purpose of political (counter)argumentation and dissemination of propaganda. True to the original hacker ethos, misinformation is seen as a threat to the democratic vision of the Internet, and as such, it must be confronted head on with tried hacktivism methods: deplatforming the “misinformers” and doxing their funding and recruitment. The majority of the hacktivists we interviewed recommended interventions for promoting misinformation literacy in addition to targeted hacking campaigns. We discuss the implications of these findings relative to the emergent recasting of hacktivism as a defense of a constructive and factual social media discourse.
“Stalking is immoral but not illegal”: Understanding Security, Cyber Crimes and Threats in Pakistan
Afaq Ashraf and — Taha, Lahore University of Management Sciences; Nida ul Habib Bajwa and Cornelius J. König, Universität des Saarlandes; Mobin Javed and Maryam Mustafa, Lahore University of Management Sciences
We explore the experiences, understandings, and perceptions of cyber-threats and crimes amongst young adults in Pakistan, focusing on their mechanisms for protecting themselves, for reporting cyber threats and for managing their digital identities. Relying on data from a qualitative study with 34 participants in combination with a repertory grid analysis with 18 participants, we map users mental models and constructs of cyber crimes and threats, their understanding of digital vulnerabilities, their own personal boundaries and their moral compasses on what constitutes an invasion of privacy of other users in a country where there is little legal legislation governing cyberspace and cyber crimes. Our findings highlight the importance of platform adaptation to accommodate the unique context of countries with limited legal mandates and reporting outlets, the ways in which digital vulnerabilities impact diverse populations, and how security and privacy design can be more inclusive.
11:00 am–12:30 pm
Evolution of Password Expiry in Companies: Measuring the Adoption of Recommendations by the German Federal Office for Information Security
Eva Gerlitz, Fraunhofer FKIE; Maximilian Häring, University of Bonn; Matthew Smith, University of Bonn and Fraunhofer FKIE; Christian Tiefenau, University of Bonn
In 2020, the German Federal Office for Information Security (BSI) updated its Password composition policy (PCP) guidelines for companies. This included the removal of password expiry, which research scholars have been discussing for at least 13 years. To analyze how the usage of password expiry in companies evolved, we conducted a study that surveyed German companies three times: eight months (n = 52 ), two years (n = 63 ), and three years (n = 80 ) after these changed recommendations. We compared our results to data gathered shortly before the change in 2019. We recruited participants via the BSI newsletter and found that 45% of the participants said their companies still use password expiry in 2023. The two main arguments were a) to increase security and b) because some stakeholders still required these regular changes. We discuss the given reasons and offer suggestions for research and guiding institutions.
12:30 pm–1:45 pm
Dissecting Nudges in Password Managers: Simple Defaults are Powerful
Samira Zibaei, Amirali Salehi-Abari, and Julie Thorpe, Ontario Tech University
Password managers offer a feature to randomly generate a new password for the user. Despite improving account security, randomly generated passwords (RGPs) are underutilized. Many password managers employ nudges to encourage users to select a randomly generated password, but the most effective nudge design is unclear. Recent work has suggested that Safari’s built-in password manager nudge might be more effective in encouraging RGP adoption than that of other browsers. However, it remains unclear what makes it more effective, and even whether this result can be attributed to Safari’s nudge design or simply its demographics. We report on a detailed large-scale study (n=853) aimed at clarifying these issues. Our results support that Safari’s nudge design is indeed more effective than Chrome’s. By dissecting the elements of Safari’s nudge, we find that its most important element is its default nudge. We additionally examine whether a social influence nudge can further enhance Safari’s RGP adoption rate. Finally, we analyze and discuss the importance of a nudge being noticed by users, and its ethical considerations. Our results inform RGP nudge designs in password managers and should also be of interest to practitioners and researchers working on other types of security nudges.
Prospects for Improving Password Selection
Joram Amador, Yiran Ma, Summer Hasama, Eshaan Lumba, Gloria Lee, and Eleanor Birrell, Pomona College
User-chosen passwords remain essential to online security, and yet users continue to choose weak, insecure passwords. In this work, we investigate whether prospect theory, a behavioral model of how people evaluate risk, can provide insights into how users choose passwords and whether it can motivate new designs for password selection mechanisms that will nudge users to select stronger passwords. We run a pair of online user studies, and we find that an intervention guided by prospect theory — -which leverages the reference-dependence effect by framing a choice of a weak password as a loss relative to choosing a stronger password — -causes approximately 25% of users to improve the strength of their password (significantly more than alternative interventions) and improves the strength of passwords users select. We also evaluate the relation between feedback provided and password decisions and between users’ mental models and password decisions. These results provide guidance for designing and implementing password selection interfaces that will significantly improve the strength of user-chosen passwords, thereby leveraging insights from prospect theory to improve the security of systems that use password-based authentication.
2:45 pm–3:15 pm
Lightning Talks
SecureGaze — Leveraging Eye Gaze to Enhance Security Mechanisms
Yasmeen Abdrabou, Lancaster University and University of the Bundeswehr Munich
A Practitioners’ Guide to Implementing Emerging Differential Privacy Tools
Anshu Singh, Government Technology Agency (GovTech), Singapore
Privacy in the Public Sector: Lessons Learned and Strategies for Success
Alan Tang, Government Technology Agency (GovTech), Singapore
Look before you Link: Privacy Risk Inspection of Open Data through a Visual Analytic Workflow
Kaustav Bhattacharjee, New Jersey Institute of Technology
Lessons Learned in Communicating Differential Privacy to Data Subjects
Mary Anne Smart, UC San Diego
3:45 pm–4:45 pm
Keynote Address
Weaponizing Technology: Examining the Importance of Privacy in an Era of Unprecedented Digital Surveillance
Sapna Khatri, University of California, Los Angeles, School of Law
The 2022 Supreme Court decision in Dobbs v. Jackson Women’s Health Organization sent shockwaves across the country. From forcing people to travel across state lines to access abortion care, to carving a path for additional rights to be challenged, the decision’s impact is far-reaching. Join us for this keynote presentation, which will explore the impact of Dobbs on the technology and privacy landscape. Specifically, we will examine how our digital footprint can paint a comprehensive picture of our daily lives — one that can easily be weaponized against us when accessing a suite of sexual and reproductive health care. This keynote will pay special attention to how our digital surveillance economy preys on marginalized communities and the need for thoughtful, privacy-protective measures as technology advances.
Sapna Khatri, J.D., is the Sears Clinical Teaching Fellow at UCLA Law School. Her policy work spans a range of privacy, gender, and reproductive justice work at the Center on Reproductive Health, Law, and Policy and the Williams Institute. She recently helped launch the nation’s first Medical Legal Partnership at a local Planned Parenthood, and UCLA Law’s inaugural Reproductive Justice Externship Seminar. Her scholarship is rooted in reproductive justice and examines technology as a weapon of reproductive oppression. Before joining UCLA Law, she worked as a Staff Attorney with the Women’s & Reproductive Rights Project at the ACLU of Illinois, and later as an Advocacy & Policy Counsel with the organization. She led amicus efforts on a religious refusals case before the IL Human Right Commission and lobbied for the successful passage of the Reproductive Health Act and Protecting Household Privacy Act. Sapna has a J.D. from Washington University, as well as a B.A. in International Studies and a B.J. in Strategic Communication from the University of Missouri-Columbia. Her publications have appeared in the Washington University Global Studies Law Review and the Chicago Sun-Times, among others. She currently also serves as a Fellow with the Internet Law & Policy Foundry.
Tuesday, August 8
9:00 am–10:00 am
Who Comes Up with this Stuff? Interviewing Authors to Understand How They Produce Security Advice
Lorenzo Neil, North Carolina State University; Harshini Sri Ramulu, The George Washington University; Yasemin Acar, Paderborn University & The George Washington University; Bradley Reaves, North Carolina State University
Users have a wealth of available security advice — — far too much, according to prior work. Experts and users alike struggle to prioritize and practice advised behaviours, negating both the advice’s purpose and potentially their security. While the problem is clear, no rigorous studies have established the root causes of overproduction, lack of prioritization, or other problems with security advice. Without understanding the causes, we cannot hope to remedy their effects.
In this paper, we investigate the processes that authors follow to develop published security advice. In a semi-structured interview study with 21 advice writers, we asked about the authors’ backgrounds, advice creation processes in their organizations, the parties involved, and how they decide to review, update, or publish new content. Among the 17 themes we identified from our interviews, we learned that authors seek to cover as much content as possible, leverage multiple diverse external sources for content, typically only review or update content after major security events, and make few if any conscious attempts to deprioritize or curate less essential content. We recommend that researchers develop methods for curating security advice and guidance on messaging for technically diverse user bases and that authors then judiciously identify key messaging ideas and schedule periodic proactive content reviews. If implemented, these actionable recommendations would help authors and users both reduce the burden of advice overproduction while improving compliance with secure computing practices.
10:00 am–10:30 am
Lightning Talks
TAM is not SAM: Acceptance of Security Technology
Ann-Marie Horcher, Northwood University
A Bermuda Triangle? Data Economy, Data Privacy, and Data Ownership
Devriş İşler, IMDEA Networks Institute
Software Product Safety Labels
Lisa LeVasseur, Internet Safety Labs
Data as Radiation: Balancing Utility and Privacy in the Digital Age
Erik Barbara, Stripe
Getting the Message Out: Considering a Connected Products Transparency Framework
Michael Fagan, Ph.D., National Institute of Standards and Technology
11:00 am–12:15 pm
GuardLens: Supporting Safer Online Browsing for People with Visual Impairments
Smirity Kaushik, Natã M. Barbosa, Yaman Yu, Tanusree Sharma, Zachary Kilhoffer, and JooYoung Seo, University of Illinois at Urbana-Champaign; Sauvik Das, Carnegie Mellon University; Yang Wang, University of Illinois at Urbana-Champaign
Visual cues play a key role in how users assess the privacy/security of a website but often remain inaccessible to people with visual impairments (PVIs), disproportionately exposing them to privacy and security risks. We employed an iterative, user-centered design process with 25 PVIs to design and evaluate GuardLens, a browser extension that improves the accessibility of privacy/security cues and helps PVIs assess a website’s legitimacy (i.e. if it is a spoof/phish). We started with a formative study to understand what privacy/security cues PVIs find helpful, and then improved GuardLens based on the results. Next, we further refined Guardlens based on a pilot study, and lastly conducted our main study to evaluate GuardLens’ efficacy. The results suggest that GuardLens, by extracting and listing pertinent privacy/security cues in one place for faster and easier access, helps PVIs quickly and accurately determine if websites are legitimate or spoofs. PVIs found cues such as domain age, search result ranking, and the presence/absence of HTTPS encryption, especially helpful. We conclude with design implications for tools to support PVIs with safe web browsing.
Iterative Design of An Accessible Crypto Wallet for Blind Users
Zhixuan Zhou, Tanusree Sharma, and Luke Emano, University of Illinois at Urbana-Champaign; Sauvik Das, Carnegie Mellon University; Yang Wang, University of Illinois at Urbana-Champaign
Crypto wallets are a key touch-point for cryptocurrency use. People use crypto wallets to make transactions, manage crypto assets, and interact with decentralized apps (dApps). However, as is often the case with emergent technologies, little attention has been paid to understanding and improving accessibility barriers in crypto wallet software. We present a series of user studies that explored how both blind and sighted individuals use MetaMask, one of the most popular non-custodial crypto wallets. We uncovered inter-related accessibility, learnability, and security issues with MetaMask. We also report on an iterative redesign of MetaMask to make it more accessible for blind users. This process involved multiple evaluations with 44 novice crypto wallet users, including 20 sighted users, 23 blind users, and one user with low vision. Our study results show notable improvements for accessibility after two rounds of design iterations. Based on the results, we discuss design implications for creating more accessible and secure crypto wallets for blind users.
ImageAlly: A Human-AI Hybrid Approach to Support Blind People in Detecting and Redacting Private Image Content
Zhuohao (Jerry) Zhang, University of Washington, Seattle; Smirity Kaushik and JooYoung Seo, University of Illinois at Urbana-Champaign; Haolin Yuan, Johns Hopkins University; Sauvik Das, Carnegie Mellon University; Leah Findlater, University of Washington, Seattle; Danna Gurari, University of Colorado Boulder; Abigale Stangl, University of Washington, Seattle; Yang Wang, University of Illinois at Urbana-Champaign
Many people who are blind take and post photos to share about their lives and connect with others. Yet, current technology does not provide blind people with accessible ways to handle when private information is unintentionally captured in their images. To explore the technology design in supporting them with this task, we developed a design probe for blind people — ImageAlly — that employs a human-AI hybrid approach to detect and redact private image content. ImageAlly notifies users when potential private information is detected in their images, using computer vision, and enables them to transfer those images to trusted sighted allies to edit the private content. In an exploratory study with pairs of blind participants and their sighted allies, we found that blind people felt empowered by ImageAlly to prevent privacy leakage in sharing images on social media. They also found other benefits from using ImageAlly, such as potentially improving their relationship with allies and giving allies the awareness of the accessibility challenges they face.
1:30 pm–2:45 pm
Distrust of big tech and a desire for privacy: Understanding the motivations of people who have voluntarily adopted secure email
Warda Usman, Jackie Hu, McKynlee Wilson, and Daniel Zappala, Brigham Young University
Secure email systems that use end-to-end encryption are the best method we have for ensuring user privacy and security in email communication. However, the adoption of secure email remains low, with previous studies suggesting mainly that secure email is too complex or inconvenient to use. However, the perspectives of those who have, in fact, chosen to use an encrypted email system are largely overlooked. To understand these perspectives, we conducted a semi-structured interview study that aims to provide a comprehensive understanding of the mindsets underlying adoption and use of secure email services. Our participants come from a variety of countries and vary in the amount of time they have been using secure email, how often they use it, and whether they use it as their primary account. Our results uncover that a defining reason for adopting a secure email system is to avoid surveillance from big tech companies. However, regardless of the complexity and accuracy of a person’s mental model, our participants rarely send and receive encrypted emails, thus not making full use of the privacy they could obtain. These findings indicate that secure email systems could potentially find greater adoption by appealing to their privacy advantages, but privacy gains will be limited until a critical mass are able to join these systems and easily send encrypted emails to each other.
Privacy Mental Models of Electronic Health Records: A German Case Study
Rebecca Panskus, Ruhr-University Bochum; Max Ninow, Leibniz University Hannover; Sascha Fahl, CISPA Helmholtz Center for Information Security; Karola Marky, Ruhr-University Bochum and Leibniz University Hannover
Central digitization of health records bears the potential for better patient care, e.g., by having more accurate diagnoses or placing less burden on patients to inform doctors about their medical history. On the flip side, having electronic health records (EHRs) has privacy implications. Hence, the data management infrastructure needs to be designed and used with care. Otherwise, patients might reject the digitization of their records, or the data might be misused. Germany, in particular, is currently introducing centralized EHRs nationwide. We took this effort as a case study and captured privacy mental models of EHRs. We present and discuss findings of an interview study where we investigated expectations towards EHRs and perceptions of the German infrastructure. Most participants were positive but skeptical, yet expressed a variety of misconceptions, especially regarding data exchange with health insurance providers and read-write access to their EHRs. Based on our results, we make recommendations for digital infrastructure providers, such as developers, system designers, and healthcare providers.
3:15 pm–4:15 pm
Exploring the Usability, Security, and Privacy of Smart Locks from the Perspective of the End User
Hussein Hazazi and Mohamed Shehab, University of North Carolina at Charlotte
Smart home devices have recently become a sought-after commodity among homeowners worldwide. Among these, smart locks have experienced a marked surge in market share, largely due to their role as a primary safeguard for homes and personal possessions. Various studies have delved into users’ apprehensions regarding the usability, security, and privacy aspects of smart homes. However, research specifically addressing these facets concerning smart locks has been limited. To bridge this research gap, we undertook a semi-structured interview study with 29 participants, each of whom had been using smart locks for a minimum period of two months. Our aim was to uncover insights regarding any possible usability, security, or privacy concerns related to smart locks, drawing from their firsthand experiences. Our findings were multifaceted, shedding light on mitigation strategies employed by users to tackle their security and privacy concerns. Moreover, we investigated the lack of concern exhibited by some participants regarding certain security or privacy risks associated with the use of smart locks, and delved into the reasons underpinning such indifference. In addition, we explored the apparent unconcern displayed by some participants towards specific security or privacy risks linked with the use of smart locks.
Investigating Security Indicators for Hyperlinking Within the Metaverse
Maximiliane Windl, LMU Munich & Munich Center for Machine Learning (MCML); Anna Scheidle, LMU Munich; Ceenu George, University of Augsburg & TU Berlin; Sven Mayer, LMU Munich & Munich Center for Machine Learning (MCML)
Security indicators, such as the padlock icon indicating SSL encryption in browsers, are established mechanisms to convey secure connections. Currently, such indicators mainly exist for browsers and mobile environments. With the rise of the metaverse, we investigate how to mark secure transitions between applications in virtual reality to so-called sub-metaverses. For this, we first conducted in-depth interviews with domain experts (N=8) to understand the general design dimensions for security indicators in virtual reality (VR). Using these insights and considering additional design constraints, we implemented the five most promising indicators and evaluated them in a user study (N=25). While the visual blinking indicator placed in the periphery performed best regarding accuracy and task completion time, participants subjectively preferred the static visual indicator above the portal. Moreover, the latter received high scores regarding understandability while still being rated low regarding intrusiveness and disturbance. Our findings contribute to a more secure and enjoyable metaverse experience.
USENIX Security ’23 Technical Sessions
Time for Change: How Clocks Break UWB Secure Ranging
Authors:
Claudio Anliker, Giovanni Camurati, and Srdjan Čapkun, ETH Zurich
Abstract:
Due to its suitability for wireless ranging, Ultra-Wide Band (UWB) has gained traction over the past years. UWB chips have been integrated into consumer electronics and considered for security-relevant use cases, such as access control or contactless payments. However, several publications in the recent past have shown that it is difficult to protect the integrity of distance measurements on the physical layer. In this paper, we identify transceiver clock imperfections as a new, important parameter that has been widely ignored so far. We present Mix-Down and Stretch-and-Advance, two novel attacks against the current (IEEE 802.15.4z) and the upcoming (IEEE 802.15.4ab) UWB standard, respectively. We demonstrate Mix-Down on commercial chips and achieve distance reductions from 10 m to 0 m. For the Stretch-and-Advance attack, we show analytically that the current proposal of IEEE 802.15.4ab allows reductions of over 90 m. To prevent the attack, we propose and analyze an effective countermeasure.
Framing Frames: Bypassing Wi-Fi Encryption by Manipulating Transmit Queues
Authors:
Domien Schepers and Aanjhan Ranganathan, Northeastern University; Mathy Vanhoef, imec-DistriNet, KU Leuven
Abstract:
Wi-Fi devices routinely queue frames at various layers of the network stack before transmitting, for instance, when the receiver is in sleep mode. In this work, we investigate how Wi-Fi access points manage the security context of queued frames. By exploiting power-save features, we show how to trick access points into leaking frames in plaintext, or encrypted using the group or an all-zero key. We demonstrate resulting attacks against several open-source network stacks. We attribute our findings to the lack of explicit guidance in managing security contexts of buffered frames in the 802.11 standards. The unprotected nature of the power-save bit in a frame’s header, which our work reveals to be a fundamental design flaw, also allows an adversary to force queue frames intended for a specific client resulting in its disconnection and trivially executing a denial-of-service attack. Furthermore, we demonstrate how an attacker can override and control the security context of frames that are yet to be queued. This exploits a design flaw in hotspot-like networks and allows the attacker to force an access points to encrypt yet to be queued frames using an adversary-chosen key, thereby bypassing Wi-Fi encryption entirely. Our attacks have a widespread impact as they affect various devices and operating systems (Linux, FreeBSD, iOS, and Android) and because they can be used to hijack TCP connections or intercept client and web traffic. Overall, we highlight the need for transparency in handling security context across the network stack layers and the challenges in doing so.
Sneaky Spy Devices and Defective Detectors: The Ecosystem of Intimate Partner Surveillance with Covert Devices
Authors:
Rose Ceccio and Sophie Stephenson, University of Wisconsin — Madison; Varun Chadha, Capital One; Danny Yuxing Huang, New York University; Rahul Chatterjee, University of Wisconsin — Madison
Abstract:
Recent anecdotal evidence suggests that abusers have begun to use covert spy devices such as nanny cameras, item trackers, and audio recorders to spy on and stalk their partners. Currently, it is difficult to combat this type of intimate partner surveillance (IPS) because we lack an understanding of the prevalence and characteristics of commercial spy devices. Additionally, it is unclear whether existing devices, apps, and tools designed to detect covert devices are effective. We observe that many spy devices and detectors can be found on mainstream retailers. Thus, in this work, we perform a systematic survey of spy devices and detection tools sold through popular US retailers. We gather 2,228 spy devices, 1,313 detection devices, and 51 detection apps, then study a representative sample through qualitative analysis as well as in-lab evaluations.
Our results show a bleak picture of the IPS ecosystem. Not only can commercial spy devices easily be used for IPS, but many of them are advertised for use in IPS and other covert surveillance. On the other hand, commercial detection devices and apps are all but defective, and while recent academic detection systems show promise, they require much refinement before they can be useful to survivors. We urge the security community to take action by designing practical, usable detection tools to detect hidden spy devices.
Going through the motions: AR/VR keylogging from user head motions
Authors:
Carter Slocum, Yicheng Zhang, Nael Abu-Ghazaleh, and Jiasi Chen, University of California, Riverside
Abstract:
Augmented Reality/Virtual Reality (AR/VR) are the next step in the evolution of ubiquitous computing after personal computers to mobile devices. Applications of AR/VR continue to grow, including education and virtual workspaces, increasing opportunities for users to enter private text, such as passwords or sensitive corporate information. In this work, we show that there is a serious security risk of typed text in the foreground being inferred by a background application, without requiring any special permissions. The key insight is that a user’s head moves in subtle ways as she types on a virtual keyboard, and these motion signals are sufficient for inferring the text that a user types. We develop a system, TyPose, that extracts these signals and automatically infers words or characters that a victim is typing. Once the sensor signals are collected, TyPose uses machine learning to segment the motion signals in time to determine word/character boundaries, and also perform inference on the words/characters themselves. Our experimental evaluation on commercial AR/VR headsets demonstrate the feasibility of this attack, both in situations where multiple users’ data is used for training (82% top-5 word classification accuracy) or when the attack is personalized to a particular victim (92% top-5 word classification accuracy). We also show that first-line defenses of reducing the sampling rate or precision of head tracking are ineffective, suggesting that more sophisticated mitigations are needed.
Tubes Among Us: Analog Attack on Automatic Speaker Identification
Authors:
Shimaa Ahmed and Yash Wani, University of Wisconsin-Madison; Ali Shahin Shamsabadi, Alan Turing Institute; Mohammad Yaghini, University of Toronto and Vector Institute; Ilia Shumailov, Vector Institute and University of Oxford; Nicolas Papernot, University of Toronto and Vector Institute; Kassem Fawaz, University of Wisconsin-Madison
Abstract:
Recent years have seen a surge in the popularity of acoustics-enabled personal devices powered by machine learning. Yet, machine learning has proven to be vulnerable to adversarial examples. A large number of modern systems protect themselves against such attacks by targeting artificiality, i.e., they deploy mechanisms to detect the lack of human involvement in generating the adversarial examples. However, these defenses implicitly assume that humans are incapable of producing meaningful and targeted adversarial examples. In this paper, we show that this base assumption is wrong. In particular, we demonstrate that for tasks like speaker identification, a human is capable of producing analog adversarial examples directly with little cost and supervision: by simply speaking through a tube, an adversary reliably impersonates other speakers in eyes of ML models for speaker identification. Our findings extend to a range of other acoustic-biometric tasks such as liveness detection, bringing into question their use in security-critical settings in real life, such as phone banking.
AIRTAG: Towards Automated Attack Investigation by Unsupervised Learning with Log Texts
Authors:
Hailun Ding, Rutgers University; Juan Zhai, University of Massachusetts Amherst; Yuhong Nan, Sun Yat-sen University; Shiqing Ma, University of Massachusetts Amherst
Abstract:
The success of deep learning (DL) techniques has led to their adoption in many fields, including attack investigation, which aims to recover the whole attack story from logged system provenance by analyzing the causality of system objects and subjects. Existing DL-based techniques, e.g., state-of-the-art one ATLAS, follow the design of traditional forensics analysis pipelines. They train a DL model with labeled causal graphs during offline training to learn benign and malicious patterns. During attack investigation, they first convert the log data to causal graphs and leverage the trained DL model to determine if an entity is part of the whole attack chain or not. This design does not fully release the power of DL. Existing works like BERT have demonstrated the superiority of leveraging unsupervised pre-trained models, achieving stateof-the-art results without costly and error-prone data labeling. Prior DL-based attacks investigation has overlooked this opportunity. Moreover, generating and operating the graphs are time-consuming and not necessary. Based on our study, these operations take around 96% of the total analysis time, resulting in low efficiency. In addition, abstracting individual log entries to graph nodes and edges makes the analysis more coarse-grained, leading to inaccurate and unstable results. We argue that log texts provide the same information as causal graphs but are fine-grained and easier to analyze.
This paper presents AIRTAG, a novel attack investigation system. It is powered by unsupervised learning with log texts. Instead of training on labeled graphs, AIRTAG leverages unsupervised learning to train a DL model on the log texts. Thus, we do not require the heavyweight and error-prone process of manually labeling logs. During the investigation, the DL model directly takes log files as inputs and predicts entities related to the attack. We evaluated AIRTAG on 19 scenarios, including single-host and multi-host attacks. Our results show the superior efficiency and effectiveness of AIRTAG compared to existing solutions. By removing graph generation and operations, AIRTAG is 2.5x faster than the state-of-the-art method, ATLAS, with 9.0% fewer false positives and 16.5% more true positives on average.
BotScreen: Trust Everybody, but Cut the Aimbots Yourself
Authors:
Minyeop Choi, KAIST; Gihyuk Ko, Cyber Security Research Center at KAIST and Carnegie Mellon University; Sang Kil Cha, KAIST and Cyber Security Research Center at KAIST
Abstract:
Aimbots, which assist players to kill opponents in FirstPerson Shooter (FPS) games, pose a significant threat to the game industry. Although there has been significant research effort to automatically detect aimbots, existing works suffer from either high server-side overhead or low detection accuracy. In this paper, we present a novel aimbot detection design and implementation that we refer to as BotScreen, which is a client-side aimbot detection solution for a popular FPS game, Counter-Strike: Global Offensive (CS:GO). BotScreen is the first in detecting aimbots in a distributed fashion, thereby minimizing the server-side overhead. It also leverages a novel deep learning model to precisely detect abnormal behaviors caused by using aimbots. We demonstrate the effectiveness of BotScreen in terms of both accuracy and performance on CS:GO. We make our tool as well as our dataset publicly available to support open science.
Exploring Tenants’ Preferences of Privacy Negotiation in Airbnb
Authors:
Zixin Wang, Zhejiang University; Danny Yuxing Huang, New York University; Yaxing Yao, University of Maryland, Baltimore County
Abstract:
Literature suggests the unmatched or conflicting privacy needs between users and bystanders in smart homes due to their different privacy concerns and priorities. A promising approach to mitigate such conflicts is through negotiation. Yet, it is not clear whether bystanders have privacy negotiation needs and if so, what factors may influence their negotiation intention and how to better support the negotiation to achieve their privacy goals. To answer these questions, we conducted a vignette study that varied across three categorical factors, including device types, device location, and duration of stay with 867 participants in the context of Airbnb. We further examined our participants’ preferences regarding with whom, when, how, and why they would like to negotiate their privacy. Our findings showed that device type remained the only factor that significantly influenced our participants’ negotiation intention. Additionally, we found our participants’ other preferences, such as they preferred to contact Airbnb hosts first to convey their privacy needs through asynchronous channels (e.g., messages and emails). We summarized design implications to fulfill tenants’ privacy negotiation needs.
HorusEye: A Realtime IoT Malicious Traffic Detection Framework using Programmable Switches
Authors:
Yutao Dong, Tsinghua Shenzhen International Graduate School, Shenzhen, China; Peng Cheng Laboratory, Shenzhen, China; Qing Li, Peng Cheng Laboratory, Shenzhen, China; Kaidong Wu and Ruoyu Li, Tsinghua Shenzhen International Graduate School, Shenzhen, China; Peng Cheng Laboratory, Shenzhen, China; Dan Zhao, Peng Cheng Laboratory, Shenzhen, China; Gareth Tyson, Hong Kong University of Science and Technology (GZ), Guangzhou, China; Junkun Peng, Yong Jiang, and Shutao Xia, Tsinghua Shenzhen International Graduate School, Shenzhen, China; Peng Cheng Laboratory, Shenzhen, China; Mingwei Xu, Tsinghua University, Beijing, China
Abstract:
The ever-growing volume of IoT traffic brings challenges to IoT anomaly detection systems. Existing anomaly detection systems perform all traffic detection on the control plane, which struggles to scale to the growing rates of traffic. In this paper, we propose HorusEye, a high throughput and accurate two-stage anomaly detection framework. In the first stage, preliminary burst-level anomaly detection is implemented on the data plane to exploit its high-throughput capability (e.g., 100Gbps). We design an algorithm that converts a trained iForest model into white list matching rules, and implement the first unsupervised model that can detect unseen attacks on the data plane. The suspicious traffic is then reported to the control plane for further investigation. To reduce the false-positive rate, the control plane carries out the second stage, where more thorough anomaly detection is performed over the reported suspicious traffic using flow-level features and a deep detection model. We implement a prototype of HorusEye and evaluate its performance through a comprehensive set of experiments. The experimental results illustrate that the data plane can detect 99% of the anomalies and offload 76% of the traffic from the control plane. Compared with the state-of-the-art schemes, our framework has superior throughput and detection performance.
TPatch: A Triggered Physical Adversarial Patch
Authors:
Wenjun Zhu and Xiaoyu Ji, USSLAB, Zhejiang University; Yushi Cheng, BNRist, Tsinghua University; Shibo Zhang and Wenyuan Xu, USSLAB, Zhejiang University
Abstract:
Autonomous vehicles increasingly utilize the vision-based perception module to acquire information about driving environments and detect obstacles. Correct detection and classification are important to ensure safe driving decisions. Existing works have demonstrated the feasibility of fooling the perception models such as object detectors and image classifiers with printed adversarial patches. However, most of them are indiscriminately offensive to every passing autonomous vehicle. In this paper, we propose TPatch, a physical adversarial patch triggered by acoustic signals. Unlike other adversarial patches, TPatch remains benign under normal circumstances but can be triggered to launch a hiding, creating or altering attack by a designed distortion introduced by signal injection attacks towards cameras. To avoid the suspicion of human drivers and make the attack practical and robust in the real world, we propose a content-based camouflage method and an attack robustness enhancement method to strengthen it. Evaluations with three object detectors, YOLO V3/V5 and Faster R-CNN, and eight image classifiers demonstrate the effectiveness of TPatch in both the simulation and the real world. We also discuss possible defenses at the sensor, algorithm, and system levels.
Anatomy of a High-Profile Data Breach: Dissecting the Aftermath of a Crypto-Wallet Case
Authors:
Svetlana Abramova and Rainer Böhme, Universität Innsbruck
Abstract:
Media reports show an alarming increase of data breaches at providers of cybersecurity products and services. Since the exposed records may reveal security-relevant data, such incidents cause undue burden and create the risk of re-victimization to individuals whose personal data gets exposed. In pursuit of examining a broad spectrum of the downstream effects on victims, we surveyed 104 persons who purchased specialized devices for the secure storage of crypto-assets and later fell victim to a breach of customer data. Our case study reveals common nuisances (i.e., spam, scams, phishing e-mails) as well as previously unseen attack vectors (e.g., involving tampered devices), which are possibly tied to the breach. A few victims report losses of digital assets as a form of the harm. We find that our participants exhibit heightened safety concerns, appear skeptical about litigation efforts, and demonstrate the ability to differentiate between the quality of the security product and the circumstances of the breach. We derive implications for the cybersecurity industry at large, and point out methodological challenges in data breach research.
Is Your Wallet Snitching On You? An Analysis on the Privacy Implications of Web3
Authors:
Christof Ferreira Torres, Fiona Willi, and Shweta Shinde, ETH Zurich
Abstract:
With the recent hype around the Metaverse and NFTs, Web3 is getting more and more popular. The goal of Web3 is to decentralize the web via decentralized applications. Wallets play a crucial role as they act as an interface between these applications and the user. Wallets such as MetaMask are being used by millions of users nowadays. Unfortunately, Web3 is often advertised as more secure and private. However, decentralized applications as well as wallets are based on traditional technologies, which are not designed with privacy of users in mind. In this paper, we analyze the privacy implications that Web3 technologies such as decentralized applications and wallets have on users. To this end, we build a framework that measures exposure of wallet information. First, we study whether information about installed wallets is being used to track users online. We analyze the top 100K websites and find evidence of 1,325 websites running scripts that probe whether users have wallets installed in their browser. Second, we measure whether decentralized applications and wallets leak the user’s unique wallet address to third-parties. We intercept the traffic of 616 decentralized applications and 100 wallets and find over 2000 leaks across 211 applications and more than 300 leaks across 13 wallets. Our study shows that Web3 poses a threat to users’ privacy and requires new designs towards more privacy-aware wallet architectures.
Capstone: A Capability-based Foundation for Trustless Secure Memory Access
Authors:
Jason Zhijingcheng Yu, National University of Singapore; Conrad Watt, University of Cambridge; Aditya Badole, Trevor E. Carlson, and Prateek Saxena, National University of Singapore
Abstract:
Capability-based memory isolation is a promising new architectural primitive. Software can access low-level memory only via capability handles rather than raw pointers, which provides a natural interface to enforce security restrictions. Existing architectural capability designs such as CHERI provide spatial safety, but fail to extend to other memory models that security-sensitive software designs may desire. In this paper, we propose Capstone, a more expressive architectural capability design that supports multiple existing memory isolation models in a trustless setup, i.e., without relying on trusted software components. We show how Capstone is well-suited for environments where privilege boundaries are fluid (dynamically extensible), memory sharing/delegation are desired both temporally and spatially, and where such needs are to be balanced with availability concerns. Capstone can also be implemented efficiently. We present an implementation sketch and through evaluation show that its overhead is below 50% in common use cases. We also prototype a functional emulator for Capstone and use it to demonstrate the runnable implementations of six real-world memory models without trusted software components: three types of enclave-based TEEs, a thread scheduler, a memory allocator, and Rust-style memory safety — all within the interface of Capstone.
Password Guessing Using Random Forest
Authors:
Ding Wang and Yunkai Zou, Nankai University; Zijian Zhang, Peking University; Kedong Xiu, Nankai University
Abstract:
Passwords are the most widely used authentication method, and guessing attacks are the most effective method for password strength evaluation. However, existing password guessing models are generally built on traditional statistics or deep learning, and there has been no research on password guessing that employs classical machine learning.
To fill this gap, this paper provides a brand new technical route for password guessing. More specifically, we re-encode the password characters and make it possible for a series of classical machine learning techniques that tackle multi-class classification problems (such as random forest, boosting algorithms and their variants) to be used for password guessing. Further, we propose RFGuess, a random-forest based framework that characterizes the three most representative password guessing scenarios (i.e., trawling guessing, targeted guessing based on personally identifiable information (PII) and on users’ password reuse behaviors).
Besides its theoretical significance, this work is also of practical value. Experiments using 13 large real-world password datasets demonstrate that our random-forest based guessing models are effective: (1) RFGuess for trawling guessing scenarios, whose guessing success rates are comparable to its foremost counterparts; (2) RFGuess-PII for targeted guessing based on PII, which guesses 20%~28% of common users within 100 guesses, outperforming its foremost counterpart by 7%~13%; (3) RFGuess-Reuse for targeted guessing based on users’ password reuse/modification behaviors, which performs the best or 2nd best among related models. We believe this work makes a substantial step toward introducing classical machine learning techniques into password guessing.
Lalaine: Measuring and Characterizing Non-Compliance of Apple Privacy Labels
Authors:
Yue Xiao, Zhengyi Li, and Yue Qin, Indiana University Bloomington; Xiaolong Bai, Orion Security Lab, Alibaba Group; Jiale Guan, Xiaojing Liao, and Luyi Xing, Indiana University Bloomington
Abstract:
As a key supplement to privacy policies that are known to be lengthy and difficult to read, Apple has launched app privacy labels, which purportedly help users more easily understand an app’s privacy practices. However, false and misleading privacy labels can dupe privacy-conscious consumers into downloading data-intensive apps, ultimately eroding the credibility and integrity of the labels. Although Apple releases requirements and guidelines for app developers to create privacy labels, little is known about whether and to what extent the privacy labels in the wild are correct and compliant, reflecting the actual data practices of iOS apps.
This paper presents the first systematic study, based on our new methodology named Lalaine, to evaluate data-flow to privacy-label flow-to-label consistency. Lalaine fully analyzed the privacy labels and binaries of 5,102 iOS apps, shedding lights on the prevalence and seriousness of privacy-label non-compliance. We provide detailed case studies and analyze root causes for privacy label non-compliance that complements prior understandings. This has led to new insights for improving privacy-label design and compliance requirements, so app developers, platform stakeholders, and policy-makers can better achieve their privacy and accountability goals. Lalaine is thoroughly evaluated for its high effectiveness and efficiency. We are responsibly reporting the results to stakeholders.
Continuous Learning for Android Malware Detection
Authors:
Yizheng Chen, Zhoujie Ding, and David Wagner, UC Berkeley
Abstract:
Machine learning methods can detect Android malware with very high accuracy. However, these classifiers have an Achilles heel, concept drift: they rapidly become out of date and ineffective, due to the evolution of malware apps and benign apps. Our research finds that, after training an Android malware classifier on one year’s worth of data, the F1 score quickly dropped from 0.99 to 0.76 after 6 months of deployment on new test samples.
In this paper, we propose new methods to combat the concept drift problem of Android malware classifiers. Since machine learning technique needs to be continuously deployed, we use active learning: we select new samples for analysts to label, and then add the labeled samples to the training set to retrain the classifier. Our key idea is, similarity-based uncertainty is more robust against concept drift. Therefore, we combine contrastive learning with active learning. We propose a new hierarchical contrastive learning scheme, and a new sample selection technique to continuously train the Android malware classifier. Our evaluation shows that this leads to significant improvements, compared to previously published methods for active learning. Our approach reduces the false negative rate from 14% (for the best baseline) to 9%, while also reducing the false positive rate (from 0.86% to 0.48%). Also, our approach maintains more consistent performance across a seven-year time period than past methods.
Formal Analysis of Session-Handling in Secure Messaging: Lifting Security from Sessions to Conversations
Authors:
Cas Cremers, CISPA Helmholtz Center for Information Security; Charlie Jacomme, Inria Paris; Aurora Naska, CISPA Helmholtz Center for Information Security
Abstract:
The building blocks for secure messaging apps, such as Signal’s X3DH and Double Ratchet (DR) protocols, have received a lot of attention from the research community. They have notably been proved to meet strong security properties even in the case of compromise such as Forward Secrecy (FS) and Post-Compromise Security (PCS). However, there is a lack of formal study of these properties at the application level. Whereas the research works have studied such properties in the context of a single ratcheting chain, a conversation between two persons in a messaging application can in fact be the result of merging multiple ratcheting chains.
In this work, we initiate the formal analysis of secure messaging taking the session-handling layer into account, and apply our approach to Sesame, Signal’s session management. We first experimentally show practical scenarios in which PCS can be violated in Signal by a clone attacker, despite its use of the Double Ratchet. We identify how this is enabled by Signal’s session-handling layer. We then design a formal model of the session-handling layer of Signal that is tractable for automated verification with the Tamarin prover, and use this model to rediscover the PCS violation and propose two provably secure mechanisms to offer stronger guarantees.
Wink: Deniable Secure Messaging
Authors:
Anrin Chakraborti, Duke University; Darius Suciu and Radu Sion, Stony Brook University
Abstract:
End-to-end encrypted (E2EE) messaging is an essential first step in providing message confidentiality. Unfortunately, all security guarantees of end-to-end encryption are lost when keys or plaintext are disclosed, either due to device compromise or coercion by powerful adversaries. This work introduces Wink, the first plausibly-deniable messaging system protecting message confidentiality from partial device compromise and compelled key disclosure. Wink can surreptitiously inject hidden messages in standard random coins, e.g., in salts, IVs, used by existing E2EE protocols. It does so as part of legitimate secure cryptographic functionality deployed inside the widely-available trusted execution environment (TEE) TrustZone. This results in hidden communication using virtually unchanged existing E2EE messaging apps, as well as strong plausible deniability. Wink has been demonstrated with multiple existing E2EE applications (including Telegram and Signal) with minimal (external) instrumentation, negligible overheads, and crucially, without changing on-wire message formats.
Three Lessons From Threema: Analysis of a Secure Messenger
Authors:
Kenneth G. Paterson, Matteo Scarlata, and Kien Tuong Truong, ETH Zurich
Abstract:
We provide an extensive cryptographic analysis of Threema, a Swiss-based encrypted messaging application with more than 10 million users and 7000 corporate customers. We present seven different attacks against the protocol in three different threat models. We discuss impact and remediations for our attacks, which have all been responsibly disclosed to Threema and patched. Finally, we draw wider lessons for developers of secure protocols.
FISHFUZZ: Catch Deeper Bugs by Throwing Larger Nets
Authors:
Han Zheng, National Computer Network Intrusion Protection Center, University of Chinese Academy of Science; School of Computer and Communication Sciences, EPFL; Zhongguancun Laboratory; Jiayuan Zhang, National Computer Network Intrusion Protection Center, University of Chinese Academy of Science; School of Computer and Communication, Lanzhou University of Technology; Yuhang Huang, National Computer Network Intrusion Protection Center, University of Chinese Academy of Science; Zezhong Ren, National Computer Network Intrusion Protection Center, University of Chinese Academy of Science; Zhongguancun Laboratory; He Wang, School of Cyber Engineering, Xidian University; Chunjie Cao, School of Cyberspace Security, Hainan University; Yuqing Zhang, National Computer Network Intrusion Protection Center, University of Chinese Academy of Science; Zhongguancun Laboratory; School of Cyberspace Security, Hainan University; School of Cyber Engineering, Xidian University; Flavio Toffalini and Mathias Payer, School of Computer and Communication Sciences, EPFL
Abstract:
Fuzzers effectively explore programs to discover bugs. Greybox fuzzers mutate seed inputs and observe their execution. Whenever a seed reaches new behavior (e.g., new code or higher execution frequency), it is stored for further mutation. Greybox fuzzers directly measure exploration and, by repeating execution of the same targets with large amounts of mutated seeds, passively exploit any lingering bugs. Directed greybox fuzzers (DGFs) narrow the search to few code locations but so far generalize distance to all targets into a single score and do not prioritize targets dynamically.
FISHFUZZ introduces an input prioritization strategy that builds on three concepts: (i) a novel multi-distance metric whose precision is independent of the number of targets, (ii) a dynamic target ranking to automatically discard exhausted targets, and (iii) a smart queue culling algorithm, based on hyperparameters, that alternates between exploration and exploitation. FISHFUZZ enables fuzzers to seamlessly scale among thousands of targets and prioritize seeds toward interesting locations, thus achieving more comprehensive program testing. To demonstrate generality, we implement FISHFUZZ over two well-established greybox fuzzers (AFL and AFL++). We evaluate FISHFUZZ by leveraging all sanitizer labels as targets. Extensively comparing FISHFUZZ against modern DGFs and coverage-guided fuzzers demonstrates that FISHFUZZ reaches higher coverage compared to the direct competitors, finds up to 282% more bugs compared with baseline fuzzers and reproduces 68.3% existing bugs faster. FISHFUZZ also discovers 56 new bugs (38 CVEs) in 47 programs.
VIPER: Spotting Syscall-Guard Variables for Data-Only Attacks
Authors:
Hengkai Ye, Song Liu, Zhechang Zhang, and Hong Hu, The Pennsylvania State University
Abstract:
As control-flow protection techniques are widely deployed, it is difficult for attackers to modify control data, like function pointers, to hijack program control flow. Instead, data-only attacks corrupt security-critical non-control data (critical data), and can bypass all control-flow protections to revive severe attacks. Previous works have explored various methods to help construct or prevent data-only attacks. However, no solution can automatically detect program-specific critical data.
In this paper, we identify an important category of critical data, syscall-guard variables, and propose a set of solutions to automatically detect such variables in a scalable manner. Syscall-guard variables determine to invoke security-related system calls (syscalls), and altering them will allow attackers to request extra privileges from the operating system. We propose branch force, which intentionally flips every conditional branch during the execution and checks whether new security-related syscalls are invoked. If so, we conduct data-flow analysis to estimate the feasibility to flip such branches through common memory errors. We build a tool, VIPER, to implement our ideas. VIPER successfully detects 34 previously unknown syscall-guard variables from 13 programs. We build four new data-only attacks on sqlite and v8, which execute arbitrary command or delete arbitrary file. VIPER completes its analysis within five minutes for most programs, showing its practicality for spotting syscall-guard variables.
Detecting and Handling IoT Interaction Threats in Multi-Platform Multi-Control-Channel Smart Homes
Authors:
Haotian Chi, Shanxi University and Temple University; Qiang Zeng, George Mason University; Xiaojiang Du, Stevens Institute of Technology
Abstract:
A smart home involves a variety of entities, such as IoT devices, automation applications, humans, voice assistants, and companion apps. These entities interact in the same physical environment, which can yield undesirable and even hazardous results, called IoT interaction threats. Existing work on interaction threats is limited to considering automation apps, ignoring other IoT control channels, such as voice commands, companion apps, and physical operations. Second, it becomes increasingly common that a smart home utilizes multiple IoT platforms, each of which has a partial view of device states and may issue conflicting commands. Third, compared to detecting interaction threats, their handling is much less studied. Prior work uses generic handling policies, which are unlikely to fit all homes. We present IoTMediator, which provides accurate threat detection and threat-tailored handling in multi-platform multi-control-channel homes. Our evaluation in two real-world homes demonstrates that IoTMediator significantly outperforms prior state-of-the-art work.
Private Proof-of-Stake Blockchains using Differentially-Private Stake Distortion
Authors:
Chenghong Wang, David Pujol, Kartik Nayak, and Ashwin Machanavajjhala, Duke University
Abstract:
Safety, liveness, and privacy are three critical properties for any private proof-of-stake (PoS) blockchain. However, prior work (SP’21) has shown that to obtain safety and liveness, a PoS blockchain must in theory forgo privacy. In particular, to obtain safety and liveness, PoS blockchains elect parties proportional to their stake, which, in turn, can potentially reveal the stake of a party even if the transaction processing mechanism is private.
In this work, we make two key contributions. First, we present the first stake inference attack that can be actually run in practice. Specifically, our attack applies to both deterministic and randomized PoS protocols and has exponentially lesser running time in comparison with the SOTA approach. Second, we use differentially private stake distortion to achieve privacy in PoS blockchains. We formulate certain privacy requirements to achieve transaction and stake privacy, and design two stake distortion mechanisms that any PoS protocol can use. Moreover, we analyze our proposed mechanisms with Ethereum 2.0, a well-known PoS blockchain that is already operating in practice. The results indicate that our mechanisms mitigate stake inference risks and, at the same time, provide reasonable privacy while preserving required safety and liveness properties.
Meta-Sift: How to Sift Out a Clean Subset in the Presence of Data Poisoning?
Authors:
Yi Zeng, Virginia Tech and SONY AI; Minzhou Pan, Himanshu Jahagirdar, and Ming Jin, Virginia Tech; Lingjuan Lyu, SONY AI; Ruoxi Jia, Virginia Tech
Abstract:
External data sources are increasingly being used to train machine learning (ML) models as the data demand increases. However, the integration of external data into training poses data poisoning risks, where malicious providers manipulate their data to compromise the utility or integrity of the model. Most data poisoning defenses assume access to a set of clean data (referred to as the base set), which could be obtained through trusted sources. But it also becomes common that entire data sources for an ML task are untrusted (e.g., Internet data). In this case, one needs to identify a subset within a contaminated dataset as the base set to support these defenses.
This paper starts by examining the performance of defenses when poisoned samples are mistakenly mixed into the base set. We analyze five representative defenses that use base sets and find that their performance deteriorates dramatically with less than 1% poisoned points in the base set. These findings suggest that sifting out a base set with \emph{high precision} is key to these defenses’ performance. Motivated by these observations, we study how precise existing automated tools and human inspection are at identifying clean data in the presence of data poisoning. Unfortunately, neither effort achieves the precision needed that enables effective defenses. Worse yet, many of the outcomes of these methods are worse than random selection.
In addition to uncovering the challenge, we take a step further and propose a practical countermeasure, Meta-Sift. Our method is based on the insight that existing poisoning attacks shift data distributions, resulting in high prediction loss when training on the clean portion of a poisoned dataset and testing on the corrupted portion. Leveraging the insight, we formulate a bilevel optimization to identify clean data and further introduce a suite of techniques to improve the efficiency and precision of the identification. Our evaluation shows that Meta-Sift can sift a clean base set with 100\% precision under a wide range of poisoning threats. The selected base set is large enough to give rise to successful defense when plugged into the existing defense techniques.
GLeeFuzz: Fuzzing WebGL Through Error Message Guided Mutation
Authors:
Hui Peng, Purdue University; Zhihao Yao and Ardalan Amiri Sani, UC Irvine; Dave (Jing) Tian, Purdue University; Mathias Payer, EPFL
Abstract:
WebGL is a set of standardized JavaScript APIs for GPU accelerated graphics. Security of the WebGL interface is paramount because it exposes remote and unsandboxed access to the underlying graphics stack (including the native GL libraries and GPU drivers) in the host OS. Unfortunately, applying state-of-the-art fuzzing techniques to the WebGL interface for vulnerability discovery is challenging because of (1) its huge input state space, and (2) the infeasibility of collecting code coverage across concurrent processes, closed-source libraries, and device drivers in the kernel.
Our fuzzing technique, GLeeFuzz, guides input mutation by error messages instead of code coverage. Our key observation is that browsers emit meaningful error messages to aid developers in debugging their WebGL programs. Error messages indicate which part of the input fails (e.g., incomplete arguments, invalid arguments, or unsatisfied dependencies between API calls). Leveraging error messages as feedback, the fuzzer effectively expands coverage by focusing mutation on erroneous parts of the input. We analyze Chrome’s WebGL implementation to identify the dependencies between error-emitting statements and rejected parts of the input, and use this information to guide input mutation. We evaluate our GLeeFuzz prototype on Chrome, Firefox, and Safari on diverse desktop and mobile OSes. We discovered 7 vulnerabilities, 4 in Chrome, 2 in Safari, and 1 in Firefox. The Chrome vulnerabilities allow a remote attacker to freeze the GPU and possibly execute remote code at the browser privilege.
Synchronization Storage Channels (S2C): Timer-less Cache Side-Channel Attacks on the Apple M1 via Hardware Synchronization Instructions
Authors:
Jiyong Yu and Aishani Dutta, University of Illinois Urbana-Champaign; Trent Jaeger, Pennsylvania State University; David Kohlbrenner, University of Washington; Christopher W. Fletcher, University of Illinois Urbana-Champaign
Abstract:
Shared caches have been a prime target for mounting crossprocess/core side-channel attacks. Fundamentally, these attacks require a mechanism to accurately observe changes in cache state. Most cache attacks rely on timing measurements to indirectly infer cache state changes, and attack success hinges on the reliability/availability of accurate timing sources. Far fewer techniques have been proposed to directly observe cache state changes without reliance on timers. Further, none of said ‘timer-less’ techniques are accessible to userspace attackers targeting modern CPUs.
This paper proposes a novel technique for mounting timerless cache attacks targeting Apple M1 CPUs named Synchronization Storage Channels (S 2C). The key observation is that the implementation of synchronization instructions, specifically Load-Linked/Store-Conditional (LL/SC), makes architectural state changes when L1 cache evictions occur. This by itself is a useful starting point for attacks, however faces multiple technical challenges when being used to perpetrate cross-core cache attacks. Specifically, LL/SC only observes L1 evictions (not shared L2 cache evictions). Further, each attacker thread can only simultaneously monitor one address at a time through LL/SC (as opposed to many). We propose a suite of techniques and reverse engineering to overcome these limitations, and demonstrate how a single-threaded userspace attacker can use LL/SC to simultaneously monitor multiple (up to 11) victim L2 sets and succeed at standard cache-attack applications, such as breaking cryptographic implementations and constructing covert channels.
InfinityGauntlet: Expose Smartphone Fingerprint Authentication to Brute-force Attack
Authors:
Yu Chen and Yang Yu, Xuanwu Lab, Tencent; Lidong Zhai, Institute of Information Engineering, Chinese Academy of Sciences
Abstract:
Billions of smartphone fingerprint authentications (SFA) occur daily for unlocking, privacy and payment. Existing threats to SFA include presentation attacks (PA) and some case-by-case vulnerabilities. The former need to know the victim’s fingerprint information (e.g., latent fingerprints) and can be mitigated by liveness detection and security policies. The latter require additional conditions (e.g., third-party screen protector, root permission) and are only exploitable for individual smartphone models.
In this paper, we conduct the first investigation on the general zero-knowledge attack towards SFA where no knowledge about the victim is needed. We propose a novelty fingerprint brute-force attack on off-the-shelf smartphones, named InfinityGauntlet. Firstly, we discover design vulnerabilities in SFA systems across various manufacturers, operating systems, and fingerprint types to achieve unlimited authentication attempts. Then, we use SPI MITM to bypass liveness detection and make automatic attempts. Finally, we customize a synthetic fingerprint generator to get a valid brute-force fingerprint dictionary.
We design and implement low-cost equipment to launch InfinityGauntlet. A proof-of-concept case study demonstrates that InfinityGauntlet can brute-force attack successfully in less than an hour without any knowledge of the victim. Additionally, empirical analysis on representative smartphones shows the scalability of our work.
InfinityGauntlet: Expose Smartphone Fingerprint Authentication to Brute-force Attack
Authors:
Yu Chen and Yang Yu, Xuanwu Lab, Tencent; Lidong Zhai, Institute of Information Engineering, Chinese Academy of Sciences
Abstract:
Billions of smartphone fingerprint authentications (SFA) occur daily for unlocking, privacy and payment. Existing threats to SFA include presentation attacks (PA) and some case-by-case vulnerabilities. The former need to know the victim’s fingerprint information (e.g., latent fingerprints) and can be mitigated by liveness detection and security policies. The latter require additional conditions (e.g., third-party screen protector, root permission) and are only exploitable for individual smartphone models.
In this paper, we conduct the first investigation on the general zero-knowledge attack towards SFA where no knowledge about the victim is needed. We propose a novelty fingerprint brute-force attack on off-the-shelf smartphones, named InfinityGauntlet. Firstly, we discover design vulnerabilities in SFA systems across various manufacturers, operating systems, and fingerprint types to achieve unlimited authentication attempts. Then, we use SPI MITM to bypass liveness detection and make automatic attempts. Finally, we customize a synthetic fingerprint generator to get a valid brute-force fingerprint dictionary.
We design and implement low-cost equipment to launch InfinityGauntlet. A proof-of-concept case study demonstrates that InfinityGauntlet can brute-force attack successfully in less than an hour without any knowledge of the victim. Additionally, empirical analysis on representative smartphones shows the scalability of our work.
Security and Privacy Failures in Popular 2FA Apps
Authors:
Conor Gilsenan, UC Berkeley / ICSI; Fuzail Shakir and Noura Alomar, UC Berkeley; Serge Egelman, UC Berkeley / ICSI
Abstract:
The Time-based One-Time Password (TOTP) algorithm is a 2FA method that is widely deployed because of its relatively low implementation costs and purported security benefits over SMS 2FA. However, users of TOTP 2FA apps face a critical usability challenge: maintain access to the secrets stored within the TOTP app, or risk getting locked out of their accounts. To help users avoid this fate, popular TOTP apps implement a wide range of backup mechanisms, each with varying security and privacy implications. In this paper, we define an assessment methodology for conducting systematic security and privacy analyses of the backup and recovery functionality of TOTP apps. We identified all general purpose Android TOTP apps in the Google Play Store with at least 100k installs that implemented a backup mechanism (n = 22). Our findings show that most backup strategies end up placing trust in the same technologies that TOTP 2FA is meant to supersede: passwords, SMS, and email. Many backup implementations shared personal user information with third parties, had serious cryptographic flaws, and/or allowed the app developers to access the TOTP secrets in plaintext. We present our findings and recommend ways to improve the security and privacy of TOTP 2FA app backup mechanisms.
CodexLeaks: Privacy Leaks from Code Generation Language Models in GitHub Copilot
Authors:
Liang Niu and Shujaat Mirza, New York University; Zayd Maradni and Christina Pöpper, New York University Abu Dhabi
Abstract:
Code generation language models are trained on billions of lines of source code to provide code generation and auto-completion features, like those offered by code assistant GitHub Copilot with more than a million users. These datasets may contain sensitive personal information — personally identifiable, private, or secret — that these models may regurgitate.
This paper introduces and evaluates a semi-automated pipeline for extracting sensitive personal information from the Codex model used in GitHub Copilot. We employ carefully-designed templates to construct prompts that are more likely to result in privacy leaks. To overcome the non-public training data, we propose a semi-automated filtering method using a blind membership inference attack. We validate the effectiveness of our membership inference approach on different code generation models. We utilize hit rate through the GitHub Search API as a distinguishing heuristic followed by human-in-the-loop evaluation, uncovering that approximately 8% (43) of the prompts yield privacy leaks. Notably, we observe that the model tends to produce indirect leaks, compromising privacy as contextual integrity by generating information from individuals closely related to the queried subject in the training corpus.
Lost at C: A User Study on the Security Implications of Large Language Model Code Assistants
Authors:
Gustavo Sandoval, Hammond Pearce, Teo Nys, Ramesh Karri, Siddharth Garg, and Brendan Dolan-Gavitt, New York University
Abstract:
Large Language Models (LLMs) such as OpenAI Codex are increasingly being used as AI-based coding assistants. Understanding the impact of these tools on developers’ code is paramount, especially as recent work showed that LLMs may suggest cybersecurity vulnerabilities. We conduct a security-driven user study (N=58) to assess code written by student programmers when assisted by LLMs. Given the potential severity of low-level bugs as well as their relative frequency in real-world projects, we tasked participants with implementing a singly-linked ‘shopping list’ structure in C. Our results indicate that the security impact in this setting (low-level C with pointer and array manipulations) is small: AI-assisted users produce critical security bugs at a rate no greater than 10% more than the control, indicating the use of LLMs does not introduce new security risks.
“Employees Who Don’t Accept the Time Security Takes Are Not Aware Enough”: The CISO View of Human-Centred Security
Authors:
Jonas Hielscher and Uta Menges, Ruhr University Bochum; Simon Parkin, TU Delft; Annette Kluge and M. Angela Sasse, Ruhr University Bochum
Abstract:
In larger organisations, the security controls and policies that protect employees are typically managed by a Chief Information Security Officer (CISO). In research, industry, and policy, there are increasing efforts to relate principles of human behaviour interventions and influence to the practice of the CISO, despite these being complex disciplines in their own right. Here we explore how well the concepts of human-centred security (HCS) have survived exposure to the needs of practice: in an action research approach we engaged with n=30 members of a Swiss-based community of CISOs in five workshop sessions over the course of 8 months, dedicated to discussing HCS. We coded and analysed over 25 hours of notes we took during the discussions. We found that CISOs far and foremost perceive HCS as what is available on the market, namely awareness and phishing simulations. While they regularly shift responsibility either to the management (by demanding more support) or to the employees (by blaming them) we see a lack of power but also silo-thinking that prevents CISOs from considering actual human behaviour and friction that security causes for employees. We conclude that industry best practices and the state-of-the-art in HCS research are not aligned.
PELICAN: Exploiting Backdoors of Naturally Trained Deep Learning Models In Binary Code Analysis
Authors:
Zhuo Zhang, Guanhong Tao, Guangyu Shen, Shengwei An, Qiuling Xu, Yingqi Liu, and Yapeng Ye, Purdue University; Yaoxuan Wu, University of California, Los Angeles; Xiangyu Zhang, Purdue University
Abstract:
Deep Learning (DL) models are increasingly used in many cyber-security applications and achieve superior performance compared to traditional solutions. In this paper, we study backdoor vulnerabilities in naturally trained models used in binary analysis. These backdoors are not injected by attackers but rather products of defects in datasets and/or training processes. The attacker can exploit these vulnerabilities by injecting some small fixed input pattern (e.g., an instruction) called backdoor trigger to their input (e.g., a binary code snippet for a malware detection DL model) such that misclassification can be induced (e.g., the malware evades the detection). We focus on transformer models used in binary analysis. Given a model, we leverage a trigger inversion technique particularly designed for these models to derive trigger instructions that can induce misclassification. During attack, we utilize a novel trigger injection technique to insert the trigger instruction(s) to the input binary code snippet. The injection makes sure that the code snippets’ original program semantics are preserved and the trigger becomes an integral part of such semantics and hence cannot be easily eliminated. We evaluate our prototype PELICAN on 5 binary analysis tasks and 15 models. The results show that PELICAN can effectively induce misclassification on all the evaluated models in both white-box and black-box scenarios. Our case studies demonstrate that PELICAN can exploit the backdoor vulnerabilities of two closed-source commercial tools.
Learning Normality is Enough: A Software-based Mitigation against Inaudible Voice Attacks
Authors:
Xinfeng Li, Xiaoyu Ji, and Chen Yan, USSLAB, Zhejiang University; Chaohao Li, USSLAB, Zhejiang University and Hangzhou Hikvision Digital Technology Co., Ltd.; Yichen Li, Hong Kong University of Science and Technology; Zhenning Zhang, University of Illinois at Urbana-Champaign; Wenyuan Xu, USSLAB, Zhejiang University
Abstract:
Inaudible voice attacks silently inject malicious voice commands into voice assistants to manipulate voice-controlled devices such as smart speakers. To alleviate such threats for both existing and future devices, this paper proposes NormDetect, a software-based mitigation that can be instantly applied to a wide range of devices without requiring any hardware modification. To overcome the challenge that the attack patterns vary between devices, we design a universal detection model that does not rely on audio features or samples derived from specific devices. Unlike existing studies’ supervised learning approach, we adopt unsupervised learning inspired by anomaly detection. Though the patterns of inaudible voice attacks are diverse, we find that benign audios share similar patterns in the time-frequency domain. Therefore, we can detect the attacks (the anomaly) by learning the patterns of benign audios (the normality). NormDetect maps spectrum features to a low-dimensional space, performs similarity queries, and replaces them with the standard feature embeddings for spectrum reconstruction. This results in a more significant reconstruction error for attacks than normality. Evaluation based on the 383,320 test samples we collected from 24 smart devices shows an average AUC of 99.48% and EER of 2.23%, suggesting the effectiveness of NormDetect in detecting inaudible voice attacks.
Network Responses to Russia’s Invasion of Ukraine in 2022: A Cautionary Tale for Internet Freedom
Authors:
Reethika Ramesh, Ram Sundara Raman, and Apurva Virkud, University of Michigan; Alexandra Dirksen, TU Braunschweig; Armin Huremagic, University of Michigan; David Fifield, unaffiliated; Dirk Rodenburg and Rod Hynes, Psiphon; Doug Madory, Kentik; Roya Ensafi, University of Michigan
Abstract:
Russia’s invasion of Ukraine in February 2022 was followed by sanctions and restrictions: by Russia against its citizens, by Russia against the world, and by foreign actors against Russia. Reports suggested a torrent of increased censorship, geoblocking, and network events affecting Internet freedom.
This paper is an investigation into the network changes that occurred in the weeks following this escalation of hostilities. It is the result of a rapid mobilization of researchers and activists, examining the problem from multiple perspectives. We develop GeoInspector, and conduct measurements to identify different types of geoblocking, and synthesize data from nine independent data sources to understand and describe various network changes. Immediately after the invasion, more than 45% of Russian government domains tested blocked access from countries other than Russia and Kazakhstan; conversely, 444 foreign websites, including news and educational domains, geoblocked Russian users. We find significant increases in Russian censorship, especially of news and social media. We find evidence of the use of BGP withdrawals to implement restrictions, and we quantify the use of a new domestic certificate authority. Finally, we analyze data from circumvention tools, and investigate their usage and blocking. We hope that our findings showing the rapidly shifting landscape of Internet splintering serves as a cautionary tale, and encourages research and efforts to protect Internet freedom.
A Study of China’s Censorship and Its Evasion Through the Lens of Online Gaming
Authors:
Yuzhou Feng, Florida International University; Ruyu Zhai, Hangzhou Dianzi University; Radu Sion, Stony Brook University; Bogdan Carbunar, Florida International University
Abstract:
For the past 20 years, China has increasingly restricted the access of minors to online games using addiction prevention systems (APSes). At the same time, and through different means, i.e., the Great Firewall of China (GFW), it also restricts general population access to the international Internet. This paper studies how these restrictions impact young online gamers, and their evasion efforts. We present results from surveys (n = 2,415) and semi-structured interviews (n = 35) revealing viable commonly deployed APS evasion techniques and APS vulnerabilities. We conclude that the APS does not work as designed, even against very young online game players, and can act as a censorship evasion training ground for tomorrow’s adults, by familiarization with and normalization of general evasion techniques, and desensitization to their dangers. Findings from these studies may further inform developers of censorship-resistant systems about the perceptions and evasion strategies of their prospective users, and help design tools that leverage services and platforms popular among the censored audience.
Timeless Timing Attacks and Preload Defenses in Tor’s DNS Cache
Authors:
Rasmus Dahlberg and Tobias Pulls, Karlstad University
Abstract:
We show that Tor’s DNS cache is vulnerable to a timeless timing attack, allowing anyone to determine if a domain is cached or not without any false positives. The attack requires sending a single TLS record. It can be repeated to determine when a domain is no longer cached to leak the insertion time. Our evaluation in the Tor network shows no instances of cached domains being reported as uncached and vice versa after 12M repetitions while only targeting our own domains. This shifts DNS in Tor from an unreliable side-channel — using traditional timing attacks with network jitter — to being perfectly reliable. We responsibly disclosed the attack and suggested two short-term mitigations.
As a long-term defense for the DNS cache in Tor against all types of (timeless) timing attacks, we propose a redesign where only an allowlist of domains is preloaded to always be cached across circuits. We compare the performance of a preloaded DNS cache to Tor’s current solution towards DNS by measuring aggregated statistics for four months from two exits (after engaging with the Tor Research Safety Board and our university ethical review process). The evaluated preload lists are variants of the following top-lists: Alexa, Cisco Umbrella, and Tranco. Our results show that four-months-old preload lists can be tuned to offer comparable performance under similar resource usage or to significantly improve shared cache-hit ratios (2–3x) with a modest increase in memory usage and resolver load compared to a 100 Mbit/s exit. We conclude that Tor’s current DNS cache is mostly a privacy harm because the majority of cached domains are unlikely to lead to cache hits but remain there to be probed by attackers.
How the Great Firewall of China Detects and Blocks Fully Encrypted Traffic
Authors:
Mingshi Wu, GFW Report; Jackson Sippe, University of Colorado Boulder; Danesh Sivakumar and Jack Burg, University of Maryland; Peter Anderson, Independent researcher; Xiaokang Wang, V2Ray Project; Kevin Bock, University of Maryland; Amir Houmansadr, University of Massachusetts Amherst; Dave Levin, University of Maryland; Eric Wustrow, University of Colorado Boulder
Abstract:
One of the cornerstones in censorship circumvention is fully encrypted protocols, which encrypt every byte of the payload in an attempt to “look like nothing”. In early November 2021, the Great Firewall of China (GFW) deployed a new censorship technique that passively detects — and subsequently blocks — fully encrypted traffic in real time. The GFW’s new censorship capability affects a large set of popular censorship circumvention protocols, including but not limited to Shadowsocks, VMess, and Obfs4. Although China had long actively probed such protocols, this was the first report of purely passive detection, leading the anti-censorship community to ask how detection was possible.
In this paper, we measure and characterize the GFW’s new system for censoring fully encrypted traffic. We find that, instead of directly defining what fully encrypted traffic is, the censor applies crude but efficient heuristics to exempt traffic that is unlikely to be fully encrypted traffic; it then blocks the remaining non-exempted traffic. These heuristics are based on the fingerprints of common protocols, the fraction of set bits, and the number, fraction, and position of printable ASCII characters. Our Internet scans reveal what traffic and which IP addresses the GFW inspects. We simulate the inferred GFW’s detection algorithm on live traffic at a university network tap to evaluate its comprehensiveness and false positives. We show evidence that the rules we inferred have good coverage of what the GFW actually uses. We estimate that, if applied broadly, it could potentially block about 0.6% of normal Internet traffic as collateral damage.
Our understanding of the GFW’s new censorship mechanism helps us derive several practical circumvention strategies. We responsibly disclosed our findings and suggestions to the developers of different anti-censorship tools, helping millions of users successfully evade this new form of blocking.
VILLAIN: Backdoor Attacks Against Vertical Split Learning
Authors:
Yijie Bai and Yanjiao Chen, Zhejiang University; Hanlei Zhang and Wenyuan Xu, Zhejing University; Haiqin Weng and Dou Goodman, Ant Group
Abstract:
Vertical split learning is a new paradigm of federated learning for participants with vertically partitioned data. In this paper, we make the first attempt to explore the possibility of backdoor attacks by a malicious participant in vertical split learning. Different from conventional federated learning, vertical split learning poses new challenges for backdoor attacks, the most looming ones being a lack of access to the training data labels and the server model. To tackle these challenges, we propose VILLAIN, a backdoor attack framework that features effective label inference and data poisoning strategies. VILLAIN realizes high inference accuracy of the target label samples for the attacker. Furthermore, VILLAIN intensifies the backdoor attack power by designing a stealthy additive trigger and introducing backdoor augmentation strategies to impose a larger influence on the server model. Our extensive evaluations on 6 datasets with comprehensive vertical split learning models and aggregation methods confirm the effectiveness of VILLAIN . It is also demonstrated that VILLAIN can resist the popular privacy inference defenses, backdoor detection or removal defenses, and adaptive defenses.
XCheck: Verifying Integrity of 3D Printed Patient-Specific Devices via Computing Tomography
Authors:
Zhiyuan Yu, Yuanhaur Chang, Shixuan Zhai, Nicholas Deily, and Tao Ju, Washington University in St. Louis; XiaoFeng Wang, Indiana University Bloomington; Uday Jammalamadaka, Rice University; Ning Zhang, Washington University in St. Louis
Abstract:
3D printing is bringing revolutionary changes to the field of medicine, with applications ranging from hearing aids to regrowing organs. As our society increasingly relies on this technology to save lives, the security of these systems is a growing concern. However, existing defense approaches that leverage side channels may require domain knowledge from computer security to fully understand the impact of the attack.
To bridge the gap, we propose XCheck, which leverages medical imaging to verify the integrity of the printed patient-specific device (PSD). XCheck follows a defense-in-depth approach and directly compares the computed tomography (CT) scan of the printed device to its original design. XCheck utilizes a voxel-based approach to build multiple layers of defense involving both 3D geometric verification and multivariate material analysis. To further enhance usability, XCheck also provides an adjustable visualization scheme that allows practitioners’ inspection of the printed object with varying tolerance thresholds to meet the needs of different applications. We evaluated the system with 47 PSDs representing different medical applications to validate the efficacy.
DDRace: Finding Concurrency UAF Vulnerabilities in Linux Drivers with Directed Fuzzing
Authors:
Ming Yuan and Bodong Zhao, Tsinghua University; Penghui Li, The Chinese University of Hong Kong; Jiashuo Liang and Xinhui Han, Peking University; Xiapu Luo, The Hong Kong Polytechnic University; Chao Zhang, Tsinghua University and Zhongguancun Lab
Abstract:
Concurrency use-after-free (UAF) vulnerabilities account for a large portion of UAF vulnerabilities in Linux drivers. Many solutions have been proposed to find either concurrency bugs or UAF vulnerabilities, but few of them can be directly applied to efficiently find concurrency UAF vulnerabilities. In this paper, we propose the first concurrency directed greybox fuzzing solution DDRace to discover concurrency UAF vulnerabilities efficiently in Linux drivers. First, we identify candidate use-after-free locations as target sites and extract the relevant concurrency elements to reduce the exploration space of directed fuzzing. Second, we design a novel vulnerability related distance metric and an interleaving priority scheme to guide the fuzzer to better explore UAF vulnerabilities and thread interleavings. Lastly, to make test cases reproducible, we design an adaptive kernel state migration scheme to assist continuous fuzzing. We have implemented a prototype of DDRace, and evaluated it on upstream Linux drivers. Results show that DDRace is effective at discovering concurrency use-after-free vulnerabilities. It finds 4 unknown vulnerabilities and 8 known ones, which is more effective than other state-of-the-art solutions.
Discovering Adversarial Driving Maneuvers against Autonomous Vehicles
Authors:
Ruoyu Song, Muslum Ozgur Ozmen, Hyungsub Kim, Raymond Muller, Z. Berkay Celik, and Antonio Bianchi, Purdue University
Abstract:
Over 33% of vehicles sold in 2021 had integrated autonomous driving (AD) systems. While many adversarial machine learning attacks have been studied against these systems, they all require an adversary to perform specific (and often unrealistic) actions, such as carefully modifying traffic signs or projecting malicious images, which may arouse suspicion if discovered. In this paper, we present Acero, a robustness-guided framework to discover adversarial maneuver attacks against autonomous vehicles (AVs). These maneuvers look innocent to the outside observer but force the victim vehicle to violate safety rules for AVs, causing physical consequences, e.g., crashing with pedestrians and other vehicles. To optimally find adversarial driving maneuvers, we formalize seven safety requirements for AD systems and use this formalization to guide our search. We also formalize seven physical constraints that ensure the adversary does not place themselves in danger or violate traffic laws while conducting the attack. Acero then leverages trajectory-similarity metrics to cluster successful attacks into unique groups, enabling AD developers to analyze the root cause of attacks and mitigate them. We evaluated Acero on two open-source AD software, openpilot and Autoware, running on the CARLA simulator. Acero discovered 219 attacks against openpilot and 122 attacks against Autoware. 73.3% of these attacks cause the victim to collide with a third-party vehicle, pedestrian, or static object.
You Can’t See Me: Physical Removal Attacks on LiDAR-based Autonomous Vehicles Driving Frameworks
Authors:
Yulong Cao, University of Michigan; S. Hrushikesh Bhupathiraju and Pirouz Naghavi, University of Florida; Takeshi Sugawara, The University of Electro-Communications; Z. Morley Mao, University of Michigan; Sara Rampazzi, University of Florida
Abstract:
Autonomous Vehicles (AVs) increasingly use LiDAR-based object detection systems to perceive other vehicles and pedestrians on the road. While existing attacks on LiDAR-based autonomous driving architectures focus on lowering the confidence score of AV object detection models to induce obstacle misdetection, our research discovers how to leverage laser-based spoofing techniques to selectively remove the LiDAR point cloud data of genuine obstacles at the sensor level before being used as input to the AV perception. The ablation of this critical LiDAR information causes autonomous driving obstacle detectors to fail to identify and locate obstacles and, consequently, induces AVs to make dangerous automatic driving decisions. In this paper, we present a method invisible to the human eye that hides objects and deceives autonomous vehicles’ obstacle detectors by exploiting inherent automatic transformation and filtering processes of LiDAR sensor data integrated with autonomous driving frameworks. We call such attacks Physical Removal Attacks (PRA), and we demonstrate their effectiveness against three popular AV obstacle detectors (Apollo, Autoware, PointPillars), and we achieve 45◦ attack capability. We evaluate the attack impact on three fusion models (Frustum-ConvNet, AVOD, and Integrated-Semantic Level Fusion) and the consequences on the driving decision using LGSVL, an industry-grade simulator. In our moving vehicle scenarios, we achieve a 92.7% success rate removing 90% of a target obstacle’s cloud points. Finally, we demonstrate the attack’s success against two popular defenses against spoofing and object hiding attacks and discuss two enhanced defense strategies to mitigate our attack.
Inducing Authentication Failures to Bypass Credit Card PINs
Authors:
David Basin, Patrick Schaller, and Jorge Toro-Pozo, ETH Zurich
Abstract:
For credit card transactions using the EMV standard, the integrity of transaction information is protected cryptographically by the credit card. Integrity checks by the payment terminal use RSA signatures and are part of EMV’s offline data authentication mechanism. Online integrity checks by the card issuer use a keyed MAC. One would expect that failures in either mechanism would always result in transaction failure, but this is not the case as offline authentication failures do not always result in declined transactions. Consequently, the integrity of transaction data that is not protected by the keyed MAC (online) cannot be guaranteed.
We show how this missing integrity protection can be exploited to bypass PIN verification for high-value Mastercard transactions. As a proof-of-concept, we have built an Android app that modifies unprotected card-sourced data, including the data relevant for cardholder verification. Using our app, we have tricked real-world terminals into downgrading from PIN verification to either no cardholder verification or (paper) signature verification, for transactions of up to 500 Swiss Francs. Our findings have been disclosed to the vendor with the recommendation to decline any transaction where offline data authentication fails.
User Awareness and Behaviors Concerning Encrypted DNS Settings in Web Browsers
Authors:
Alexandra Nisenoff, Carnegie Mellon University and University of Chicago; Ranya Sharma and Nick Feamster, University of Chicago
Abstract:
Recent developments to encrypt the Domain Name System (DNS) have resulted in major browser and operating system vendors deploying encrypted DNS functionality, often enabling various configurations and settings by default. In many cases, default encrypted DNS settings have implications for performance and privacy; for example, Firefox’s default DNS setting sends all of a user’s DNS queries to Cloudflare, potentially introducing new privacy vulnerabilities. In this paper, we confirm that most users are unaware of these developments — with respect to the rollout of these new technologies, the changes in default settings, and the ability to customize encrypted DNS configuration to balance user preferences between privacy and performance. Our findings suggest several important implications for the designers of interfaces for encrypted DNS functionality in both browsers and operating systems, to help improve user awareness concerning these settings, and to ensure that users retain the ability to make choices that allow them to balance tradeoffs concerning DNS privacy and performance.
Fourteen Years in the Life: A Root Server’s Perspective on DNS Resolver Security
Authors:
Alden Hilton, Sandia National Laboratories; Casey Deccio, Brigham Young University; Jacob Davis, Sandia National Laboratories
Abstract:
We consider how the DNS security and privacy landscape has evolved over time, using data collected annually at A-root between 2008 and 2021. We consider issues such as deployment of security and privacy mechanisms, including source port randomization, TXID randomization, DNSSEC, and QNAME minimization. We find that achieving general adoption of new security practices is a slow, ongoing process. Of particular note, we find a significant number of resolvers lacking nearly all of the security mechanisms we considered, even as late as 2021. Specifically, in 2021, over 4% of the resolvers analyzed were unprotected by either source port randomization, DNSSEC validation, DNS cookies, or 0x20 encoding. Encouragingly, we find that the volume of traffic from resolvers with secure practices is significantly higher than that of other resolvers.
Token Spammers, Rug Pulls, and Sniper Bots: An Analysis of the Ecosystem of Tokens in Ethereum and in the Binance Smart Chain (BNB)
Authors:
Federico Cernera, Massimo La Morgia, Alessandro Mei, and Francesco Sassi, Sapienza University of Rome
Abstract:
In this work, we perform a longitudinal analysis of the BNB Smart Chain and Ethereum blockchain from their inception to March 2022. We study the ecosystem of the tokens and liquidity pools, highlighting analogies and differences between the two blockchains. We discover that about 60% of tokens are active for less than one day. Moreover, we find that 1% of addresses create an anomalous number of tokens (between 20% and 25%). We discover that these tokens are used as disposable tokens to perform a particular type of rug pull, which we call 1-day rug pull. We quantify the presence of this operation on both blockchains discovering its prevalence on the BNB Smart Chain. We estimate that 1-day rug pulls generated $240 million in profits. Finally, we present sniper bots, a new kind of trader bot involved in these activities, and we detect their presence and quantify their activity in the rug pull operations.
Beyond Typosquatting: An In-depth Look at Package Confusion
Authors:
Shradha Neupane, Worcester Polytechnic Institute; Grant Holmes, Elizabeth Wyss, and Drew Davidson, University of Kansas; Lorenzo De Carli, University of Calgary
Abstract:
Package confusion incidents — where a developer is misled into importing a package other than the intended one — are one of the most severe issues in supply chain security with significant security implications, especially when the wrong package has malicious functionality. While the prevalence of the issue is generally well-documented, little work has studied the range of mechanisms by which confusion in a package name could arise or be employed by an adversary. In our work, we present the first comprehensive categorization of the mechanisms used to induce confusion, and we show how this understanding can be used for detection.
First, we use qualitative analysis to identify and rigorously define 13 categories of confusion mechanisms based on a dataset of 1200+ documented attacks. Results show that, while package confusion is thought to mostly exploit typing errors, in practice attackers use a variety of mechanisms, many of which work at semantic, rather than syntactic, level. Equipped with our categorization, we then define detectors for the discovered attack categories, and we evaluate them on the entire npm package set.
Evaluation of a sample, performed through an online survey, identifies a subset of highly effective detection rules which (i) return high-quality matches (77% matches marked as potentially or highly confusing, and 18% highly confusing) and (ii) generate low warning overhead (1 warning per 100M+ package pairs). Comparison with state-of-the-art reveals that the large majority of such pairs are not flagged by existing tools. Thus, our work has the potential to concretely improve the identification of confusable package names in the wild.
Eavesdropping Mobile App Activity via Radio-Frequency Energy Harvesting
Authors:
Tao Ni, Shenzhen Research Institute, City University of Hong Kong, and Department of Computer Science, City University of Hong Kong; Guohao Lan, Department of Software Technology, Delft University of Technology; Jia Wang, College of Computer Science and Software Engineering, Shenzhen University; Qingchuan Zhao, Department of Computer Science, City University of Hong Kong; Weitao Xu, Shenzhen Research Institute, City University of Hong Kong, and Department of Computer Science, City University of Hong Kong
Abstract:
Radio-frequency (RF) energy harvesting is a promising technology for Internet-of-Things (IoT) devices to power sensors and prolong battery life. In this paper, we present a novel side-channel attack that leverages RF energy harvesting signals to eavesdrop mobile app activities. To demonstrate this novel attack, we propose AppListener, an automated attack framework that recognizes fine-grained mobile app activities from harvested RF energy. The RF energy is harvested from a custom-built RF energy harvester which generates voltage signals from ambient Wi-Fi transmissions, and app activities are recognized from a three-tier classification algorithm. We evaluate AppListener with four mobile devices running 40 common mobile apps (e.g., YouTube, Facebook, and WhatsApp) belonging to five categories (i.e., video, music, social media, communication, and game); each category contains five application-specific activities. Experiment results show that AppListener achieves over 99% accuracy in differentiating four different mobile devices, over 98% accuracy in classifying 40 different apps, and 86.7% accuracy in recognizing five sets of application-specific activities. Moreover, a comprehensive study is conducted to show AppListener is robust to a number of impact factors, such as distance, environment, and non-target connected devices. Practices of integrating AppListener into commercial IoT devices also demonstrate that it is easy to deploy. Finally, countermeasures are presented as the first step to defend against this novel attack.
Defining “Broken”: User Experiences and Remediation Tactics When Ad-Blocking or Tracking-Protection Tools Break a Website’s User Experience
Authors:
Alexandra Nisenoff, University of Chicago and Carnegie Mellon University; Arthur Borem, Madison Pickering, Grant Nakanishi, Maya Thumpasery, and Blase Ur, University of Chicago
Abstract:
To counteract the ads and third-party tracking ubiquitous on the web, users turn to blocking tools — ad-blocking and tracking-protection browser extensions and built-in features. Unfortunately, blocking tools can cause non-ad, non-tracking elements of a website to degrade or fail, a phenomenon termed breakage. Examples include missing images, non-functional buttons, and pages failing to load. While the literature frequently discusses breakage, prior work has not systematically mapped and disambiguated the spectrum of user experiences subsumed under breakage, nor sought to understand how users experience, prioritize, and attempt to fix breakage. We fill these gaps. First, through qualitative analysis of 18,932 extension-store reviews and GitHub issue reports for ten popular blocking tools, we developed novel taxonomies of 38 specific types of breakage and 15 associated mitigation strategies. To understand subjective experiences of breakage, we then conducted a 95-participant survey. Nearly all participants had experienced various types of breakage, and they employed an array of strategies of variable effectiveness in response to specific types of breakage in specific contexts. Unfortunately, participants rarely notified anyone who could fix the root causes. We discuss how our taxonomies and results can improve the comprehensiveness and prioritization of ongoing attempts to automatically detect and fix breakage.
Silent Bugs Matter: A Study of Compiler-Introduced Security Bugs
Authors:
Jianhao Xu, Nanjing University; Kangjie Lu, University of Minnesota; Zhengjie Du, Zhu Ding, and Linke Li, Nanjing University; Qiushi Wu, University of Minnesota; Mathias Payer, EPFL; Bing Mao, Nanjing University
Abstract:
Compilers assure that any produced optimized code is semantically equivalent to the original code. However, even “correct” compilers may introduce security bugs as security properties go beyond translation correctness. Security bugs introduced by such correct compiler behaviors can be disputable; compiler developers expect users to strictly follow language specifications and understand all assumptions, while compiler users may incorrectly assume that their code is secure. Such bugs are hard to find and prevent, especially when it is unclear whether they should be fixed on the compiler or user side. Nevertheless, these bugs are real and can be severe, thus should be studied carefully.
We perform a comprehensive study on compiler-introduced security bugs (CISB) and their root causes. We collect a large set of CISB in the wild by manually analyzing 4,827 potential bug reports of the most popular compilers (GCC and Clang), distilling them into a taxonomy of CISB. We further conduct a user study to understand how compiler users view compiler behaviors. Our study shows that compiler-introduced security bugs are common and may have serious security impacts. It is unrealistic to expect compiler users to understand and comply with compiler assumptions. For example, the “no-undefined-behavior” assumption has become a nightmare for users and a major cause of CISB.
Place Your Locks Well: Understanding and Detecting Lock Misuse Bugs
Authors:
Yuandao Cai, Peisen Yao, Chengfeng Ye, and Charles Zhang, The Hong Kong University of Science and Technology
Abstract:
Modern multi-threaded software systems commonly leverage locks to prevent concurrency bugs. Nevertheless, due to the complexity of writing the correct concurrent code, using locks itself is often error-prone. In this work, we investigate a general variety of lock misuses. Our characteristic study of existing CVE IDs reveals that lock misuses can inflict concurrency errors and even severe security issues, such as denial-of-service and memory corruption. To alleviate the threats, we present a practical static analysis framework, namely Lockpick, which consists of two core stages to effectively detect misused locks. More specifically, Lockpick first conducts path-sensitive typestate analysis, tracking lock-state transitions and interactions to identify sequential typestate violations. Guided by the preceding results, Lockpick then performs concurrency-aware detection to pinpoint various lock misuse errors, effectively reasoning about the thread interleavings of interest. The results are encouraging — we have used Lockpick to uncover 203 unique and confirmed lock misuses across a broad spectrum of impactful open-source systems, such as OpenSSL, the Linux kernel, PostgreSQL, MariaDB, FFmpeg, Apache HTTPd, and FreeBSD. Three exciting results are that those confirmed lock misuses are long-latent, hiding for 7.4 years on average; in total, 16 CVE IDs have been assigned for the severe errors uncovered; and Lockpick can flag many real bugs missed by the previous tools with significantly fewer false positives.
URET: Universal Robustness Evaluation Toolkit (for Evasion)
Authors:
Kevin Eykholt, Taesung Lee, Douglas Schales, Jiyong Jang, and Ian Molloy, IBM Research; Masha Zorin, University of Cambridge
Abstract:
Machine learning models are known to be vulnerable to adversarial evasion attacks as illustrated by image classification models. Thoroughly understanding such attacks is critical in order to ensure the safety and robustness of critical AI tasks. However, most evasion attacks are difficult to deploy against a majority of AI systems because they have focused on image domain with only few constraints. An image is composed of homogeneous, numerical, continuous, and independent features, unlike many other input types to AI systems used in practice. Furthermore, some input types include additional semantic and functional constraints that must be observed to generate realistic adversarial inputs. In this work, we propose a new framework to enable the generation of adversarial inputs irrespective of the input type and task domain. Given an input and a set of pre-defined input transformations, our framework discovers a sequence of transformations that result in a semantically correct and functional adversarial input. We demonstrate the generality of our approach on several diverse machine learning tasks with various input representations. We also show the importance of generating adversarial examples as they enable the deployment of mitigation techniques.
GigaDORAM: Breaking the Billion Address Barrier
Authors:
Brett Falk, University of Pennsylvania; Rafail Ostrovsky, Matan Shtepel, and Jacob Zhang, University of California, Los Angeles
Abstract:
We design and implement GigaDORAM, a novel 3-server Distributed Oblivious Random Access Memory (DORAM) protocol. Oblivious RAM allows a client to read and write to memory on an untrusted server, while ensuring the server itself learns nothing about the client’s access pattern. Distributed Oblivious RAM (DORAM) allows a group of servers to efficiently access a secret-shared array at a secret-shared index.
A recent generation of DORAM implementations (e.g. FLORAM, DuORAM) have focused on building DORAM protocols based on Function Secret-Sharing (FSS). These protocols have low communication complexity and low round complexity but linear computational complexity of the servers. Thus, they work for moderate size databases, but at a certain size these FSS-based protocols become computationally inefficient.
In this work, we introduce GigaDORAM, a hierarchical-solution-based DORAM featuring poly-logarithmic computation and communication, but with an over 100× reduction in rounds per query compared to previous hierarchical DORAM protocols. In our implementation, we show that for moderate to large databases where FSS-based solutions become computation bound, our protocol is orders of magnitude more efficient than the best existing DORAM protocols. When N = 231, our DORAM is able to perform over 700 queries per second.
PATROL: Provable Defense against Adversarial Policy in Two-player Games
Authors:
Wenbo Guo, UC Berkeley; Xian Wu, Northwestern University; Lun Wang, UC Berkeley; Xinyu Xing, Northwestern University; Dawn Song, UC Berkeley
Abstract:
Recent advances in deep reinforcement learning (DRL) takes artificial intelligence to the next level, from making individual decisions to accomplishing sophisticated tasks via sequential decision makings, such as defeating world-class human players in various games and making real-time trading decisions in stock markets. Following these achievements, we have recently witnessed a new attack specifically designed against DRL. Recent research shows by learning and controlling an adversarial agent/policy, an attacker could quickly discover a victim agent’s weaknesses and thus force it to fail its task.
Due to differences in the threat model, most existing defenses proposed for deep neural networks (DNN) cannot be migrated to train robust policies against adversarial policy attacks. In this work, we draw insights from classical game theory and propose the first provable defense against such attacks in two-player competitive games. Technically, we first model the robust policy training problem as finding the nash equilibrium (NE) point in the entire policy space. Then, we design a novel policy training method to search for the NE point in complicated DRL tasks. Finally, we theoretically prove that our proposed method could guarantee the lowerbound performance of the trained agents against arbitrary adversarial policy attacks. Through extensive evaluations, we demonstrate that our method significantly outperforms existing policy training methods in adversarial robustness and performance in non-adversarial settings.
Egg Hunt in Tesla Infotainment: A First Look at Reverse Engineering of Qt Binaries
Authors:
Haohuang Wen and Zhiqiang Lin, The Ohio State University
Abstract:
As one of the most popular C++ extensions for developing graphical user interface (GUI) based applications, Qt has been widely used in desktops, mobiles, IoTs, automobiles, etc. Although existing binary analysis platforms (e.g., angr and Ghidra) could help reverse engineer Qt binaries, they still need to address many fundamental challenges such as the recovery of control flow graphs and symbols. In this paper, we take a first look at understanding the unique challenges and opportunities in Qt binary analysis, developing enabling techniques, and demonstrating novel applications. In particular, although callbacks make control flow recovery challenging, we notice that Qt’s signal and slot mechanism can be used to recover function callbacks. More interestingly, Qt’s unique dynamic introspection can also be repurposed to recover semantic symbols. Based on these insights, we develop QtRE for function callback and semantic symbol recovery for Qt binaries. We have tested QtRE with two suites of Qt binaries: Linux KDE and the Tesla Model S firmware, where QtRE additionally recovered 10,867 callback instances and 24,973 semantic symbols from 123 binaries, which cannot be identified by existing tools. We demonstrate a novel application of using QtRE to extract hidden commands from a Tesla Model S firmware. QtRE discovered 12 hidden commands including five unknown to the public, which can potentially be exploited to manipulate vehicle settings.
Rods with Laser Beams: Understanding Browser Fingerprinting on Phishing Pages
Authors:
Iskander Sanchez-Rola and Leyla Bilge, Norton Research Group; Davide Balzarotti, EURECOM; Armin Buescher, Crosspoint Labs; Petros Efstathopoulos, Norton Research Group
Abstract:
Phishing is one of the most common forms of social engineering attacks and is regularly used by criminals to compromise millions of accounts every year. Numerous solutions have been proposed to detect or prevent identity thefts, but phishers have responded by improving their methods and adopting more sophisticated techniques. One of the most recent advancements is the use of browser fingerprinting. In particular, fingerprinting techniques can be used as an additional piece of information that complements the stolen credentials This is confirmed by the fact that credentials with fingerprint data are sold for higher prices in underground markets.
To understand the real extent of this phenomenon, we conducted the largest study of the phishing ecosystem in the topic by analyzing more than 1.7M recent phishing pages that emerged over the course of 21 months. In our systematic study, we performed detailed measurements to estimate the prevalence of fingerprinting techniques in phishing pages.
We found that more than one in four phishing pages adopt some form of fingerprinting. This seems an ever growing trend as the percentage of pages using these techniques steadily increased during the analysis period (last month doubling what detected in the first month)
Network Detection of Interactive SSH Impostors Using Deep Learning
Authors:
Julien Piet, UC Berkeley and Corelight; Aashish Sharma, Lawrence Berkeley National Laboratory; Vern Paxson, Corelight and UC Berkeley; David Wagner, UC Berkeley
Abstract:
Impostors who have stolen a user’s SSH login credentials can inflict significant harm to the systems to which the user has remote access. We consider the problem of identifying such imposters when they conduct interactive SSH logins by detecting discrepancies in the timing and sizes of the client-side data packets, which generally reflect the typing dynamics of the person sending keystrokes over the connection.
The problem of keystroke authentication using unknown freeform text has received limited-scale study to date. We develop a supervised approach based on using a transformer (a sequence model from the ML deep learning literature) and a custom “partition layer” that, once trained, takes as input the sequence of client packet timings and lengths, plus a purported user label, and outputs a decision regarding whether the sequence indeed corresponds to that user. We evaluate the model on 5 years of labeled SSH PCAPs (spanning 3,900 users) from a large research institute. While the performance specifics vary with training levels, we find that in all cases the model can catch over 95% of (injected) imposters within the first minutes of a connection, while incurring a manageable level of false positives per day.
Network Detection of Interactive SSH Impostors Using Deep Learning
Authors:
Julien Piet, UC Berkeley and Corelight; Aashish Sharma, Lawrence Berkeley National Laboratory; Vern Paxson, Corelight and UC Berkeley; David Wagner, UC Berkeley
Abstract:
Impostors who have stolen a user’s SSH login credentials can inflict significant harm to the systems to which the user has remote access. We consider the problem of identifying such imposters when they conduct interactive SSH logins by detecting discrepancies in the timing and sizes of the client-side data packets, which generally reflect the typing dynamics of the person sending keystrokes over the connection.
The problem of keystroke authentication using unknown freeform text has received limited-scale study to date. We develop a supervised approach based on using a transformer (a sequence model from the ML deep learning literature) and a custom “partition layer” that, once trained, takes as input the sequence of client packet timings and lengths, plus a purported user label, and outputs a decision regarding whether the sequence indeed corresponds to that user. We evaluate the model on 5 years of labeled SSH PCAPs (spanning 3,900 users) from a large research institute. While the performance specifics vary with training levels, we find that in all cases the model can catch over 95% of (injected) imposters within the first minutes of a connection, while incurring a manageable level of false positives per day.
VeriZexe: Decentralized Private Computation with Universal Setup
Authors:
Alex Luoyuan Xiong, Espresso Systems, National University of Singapore; Binyi Chen and Zhenfei Zhang, Espresso Systems; Benedikt Bünz, Espresso Systems, Stanford University; Ben Fisch, Espresso Systems, Yale University; Fernando Krell and Philippe Camacho, Espresso Systems
Abstract:
Traditional blockchain systems execute program state transitions on-chain, requiring each network node participating in state-machine replication to re-compute every step of the program when validating transactions. This limits both scalability and privacy. Recently, Bowe et al. introduced a primitive called decentralized private computation (DPC) and provided an instantiation called Zexe, which allows users to execute arbitrary computations off-chain without revealing the program logic to the network. Moreover, transaction validation takes only constant time, independent of the off-chain computation. However, Zexe required a separate trusted setup for each application, which is highly impractical. Prior attempts to remove this per-application setup incurred significant performance loss.
We propose a new DPC instantiation VeriZexe that is highly efficient and requires only a single universal setup to support an arbitrary number of applications. Our benchmark improves the state-of-the-art by 9x in transaction generation time and by 3.4x in memory usage. Along the way, we also design efficient gadgets for variable-base multi-scalar multiplication and modular arithmetic within the Plonk constraint system, leading to a Plonk verifier gadget using only ∼ 21k Plonk constraints.
HOMESPY: The Invisible Sniffer of Infrared Remote Control of Smart TVs
Authors:
Kong Huang, YuTong Zhou, and Ke Zhang, The Chinese University of Hong Kong; Jiacen Xu, University of California, Irvine; Jiongyi Chen, National University of Defense Technology; Di Tang, Indiana University Bloomington; Kehuan Zhang, The Chinese University of Hong Kong
Abstract:
Infrared (IR) remote control is a widely used technology at home due to its simplicity and low cost. Most considered it to be “secure’’ because of the line-of-sight usage within the home. In this paper, we revisit the security of IR remote control schemes and examine their security assumptions under the settings of internet-connected smart homes. We focus on two specific questions: (1) whether IR signals could be sniffed by an IoT device; and (2) what information could be leaked out through the sniffed IR control signals.
To answer these questions, we design a sniff module using a commercial-off-the-shelf IR receiver on a Raspberry Pi and show that the Infrared (IR) signal emanating from the remote control of a Smart TV can be captured by one of the nearby IoT devices, for example, a smart air-conditioner, even the signal is not aimed at the air-conditioner. The IR signal range and receiving angle are larger than most have thought. We also developed algorithms to extract semantic information from the sniffed IR control signals, and evaluated with real-world applications. The results showed that lots of sensitive information could be leaked out through the sniffed IR control signals, including account name and password, PIN code, and even payment information.
Remote Attacks on Speech Recognition Systems Using Sound from Power Supply
Authors:
Lanqing Yang, Xinqi Chen, Xiangyong Jian, Leping Yang, Yijie Li, Qianfei Ren, Yi-Chao Chen, and Guangtao Xue, Shanghai Jiao Tong University; Xiaoyu Ji, Zhejiang University
Abstract:
Speech recognition (SR) systems are used on smart phones and speakers to make inquiries, compose emails, and initiate phone calls. However, they also impose a serious security risk. Researchers have demonstrated that the introduction of certain sounds can threaten the security of SR systems. Nonetheless, most of those methods require that the attacker approach to within a short distance of the victim, thereby limiting the applicability of such schemes. Other researchers have attacked SR systems remotely using peripheral devices (e.g., lasers); however, those methods require line of sight access and an always-on speaker in the vicinity of the victim. To the best of our knowledge, this paper presents the first-ever scheme, named SingAttack, in which SR systems are manipulated by human-like sounds generated in the switching mode power supply of the victim’s device. The fact that attack signals are transmitted via the power grid enables long-range attacks on existing SR systems. The proposed SingAttack system does not rely on extraneous hardware or unrealistic assumptions pertaining to device access. In experiments on ten SR systems, SingAttack achieved Mel-Cepstral Distortion of 7.8 from an attack initiated at a distance of 23m.
Near-Ultrasound Inaudible Trojan (Nuit): Exploiting Your Speaker to Attack Your Microphone
Authors:
Qi Xia and Qian Chen, University of Texas at San Antonio; Shouhuai Xu, University of Colorado Colorado Springs
Abstract:
Voice Control Systems (VCSs) offer a convenient interface for issuing voice commands to smart devices. However, VCS security has yet to be adequately understood and addressed as evidenced by the presence of two classes of attacks: (i) inaudible attacks, which can be waged when the attacker and the victim are in proximity to each other; and (ii) audible attacks, which can be waged remotely by embedding attack signals into audios. In this paper, we introduce a new class of attacks, dubbed near-ultrasound inaudible trojan (Nuit). Nuit attacks achieve the best of the two classes of attacks mentioned above: they are inaudible and can be waged remotely. Moreover, Nuit attacks can achieve end-to-end unnoticeability, which is important but has not been paid due attention in the literature. Another feature of Nuit attacks is that they exploit victim speakers to attack victim microphones and their associated VCSs, meaning the attacker does not need to use any special speaker. We demonstrate the feasibility of Nuit attacks and propose an effective defense against them.
A Research Framework and Initial Study of Browser Security for the Visually Impaired
Authors:
Elaine Lau and Zachary Peterson, Cal Poly, San Luis Obispo
Abstract:
The growth of web-based malware and phishing attacks has catalyzed significant advances in the research and use of interstitial warning pages and modals by a browser prior to loading the content of a suspect site. These warnings commonly use visual cues to attract users’ attention, including specialized iconography, color, and the placement and size of buttons to communicate the importance of the scenario. While the efficacy of visual techniques has improved safety for sighted users, these techniques are unsuitable for blind and visually impaired users. We attribute this not to a lack of interest or technical capability by browser manufactures, where universal design is a core tenet of their engineering practices, but instead a reflection of the very real dearth of research literature to inform their choices, exacerbated by a deficit of clear methodologies for conducting studies with this population. Indeed, the challenges are manifold. In this paper, we analyze and address the methodological challenges of conducting security and privacy research with a visually impaired population, and contribute a new set of methodological best practices when conducting a study of this kind. Using our methodology, we conduct a preliminary study analyzing the experiences of the visually impaired with browser security warnings, perform a thematic analysis identifying common challenges visually impaired users experience, and present some initial solutions that could improve security for this population.
Uncontained: Uncovering Container Confusion in the Linux Kernel
Authors:
Jakob Koschel, Vrije Universiteit Amsterdam; Pietro Borrello and Daniele Cono D’Elia, Sapienza University of Rome; Herbert Bos and Cristiano Giuffrida, Vrije Universiteit Amsterdam
Abstract:
Type confusion bugs are a common source of security problems whenever software makes use of type hierarchies, as an inadvertent downcast to an incompatible type is hard to detect at compile time and easily leads to memory corruption at runtime. Where existing research mostly studies type confusion in the context of object-oriented languages such as C++, we analyze how similar bugs affect complex C projects such as the Linux kernel. In particular, structure embedding emulates type inheritance between typed structures. Downcasting in such cases consists of determining the containing structure from the embedded one, and, like its C++ counterpart, may well lead to bad casting to an incompatible type.
In this paper, we present uncontained, a systematic, two-pronged solution to discover type confusion vulnerabilities resulting from incorrect downcasting on structure embeddings — which we call container confusion. First, we design a novel sanitizer to dynamically detect such issues and evaluate it on the Linux kernel, where we find as many as 11 container confusion bugs. Using the patterns in the bugs detected by the sanitizer, we then develop a static analyzer to find similar bugs in code that dynamic analysis fails to reach and detect another 78 bugs. We reported and proposed patches for all the bugs (with 102 patches already merged and 6 CVEs assigned), cooperating with the Linux kernel maintainers towards safer design choices for container manipulation.
“I’m going to trust this until it burns me” Parents’ Privacy Concerns and Delegation of Trust in K-8 Educational Technology
Authors:
Victoria Zhong, New York University; Susan McGregor, Columbia University; Rachel Greenstadt, New York University
Abstract:
After COVID-19 restrictions forced an almost overnight transition to distance learning for students of all ages, education software became a target for data breaches, with incidents like the Illuminate data breach affecting millions of students nationwide and over 820,000 current and former students in New York City (NYC) alone. Despite a general return to in-person schooling, some schools continue to rely on remote-learning technologies, with NYC even using remote learning during weather-related closures or “snow days.” Given the ongoing use of these classroom technologies, we sought to understand parents’ awareness of their security and privacy risks. We also wanted to know what concerns parents had around their childrens’ use of these tools, and what informed these concerns. To answer these questions, we interviewed 18 NYC parents with children in grades K-8. We found that though the COVID-19 pandemic was the first exposure to remote learning technologies for many children and some parents, there was insufficient guidance and training around them provided for children, parents, and educators. We also found that participating parents implicitly trusted schools and the Department of Education (DOE) to keep their children — and their children’s data — safe, and therefore rarely reported privacy and security concerns about classroom technologies. At the same time, however, they described many situations that indicated privacy and security risks with respect to classroom technologies.
A Two-Decade Retrospective Analysis of a University’s Vulnerability to Attacks Exploiting Reused Passwords
Authors:
Alexandra Nisenoff, University of Chicago / Carnegie Mellon University; Maximilian Golla, University of Chicago / Max Planck Institute for Security and Privacy; Miranda Wei, University of Chicago / University of Washington; Juliette Hainline, Hayley Szymanek, Annika Braun, Annika Hildebrandt, Blair Christensen, David Langenberg, and Blase Ur, University of Chicago
Abstract:
Credential-guessing attacks often exploit passwords that were reused across a user’s online accounts. To learn how organizations can better protect users, we retrospectively analyzed our university’s vulnerability to credential-guessing attacks across twenty years. Given a list of university usernames, we searched for matches in both data breaches from hundreds of websites and a dozen large compilations of breaches. After cracking hashed passwords and tweaking guesses, we successfully guessed passwords for 32.0% of accounts matched to a university email address in a data breach, as well as 6.5% of accounts where the username (but not necessarily the domain) matched. Many of these accounts remained vulnerable for years after the breached data was leaked, and passwords found verbatim in breaches were nearly four times as likely to have been exploited (i.e., suspicious account activity was observed) than tweaked guesses. Over 70 different data breaches and various username-matching strategies bootstrapped correct guesses. In surveys of 40 users whose passwords we guessed, many users were unaware of the risks to their university account or that their credentials had been breached. This analysis of password reuse at our university provides pragmatic advice for organizations to protect accounts.
Person Re-identification in 3D Space: A WiFi Vision-based Approach
Authors:
Yili Ren and Yichao Wang, Florida State University; Sheng Tan, Trinity University; Yingying Chen, Rutgers University; Jie Yang, Florida State University
Abstract:
Person re-identification (Re-ID) has become increasingly important as it supports a wide range of security applications. Traditional person Re-ID mainly relies on optical camera-based systems, which incur several limitations due to the changes in the appearance of people, occlusions, and human poses. In this work, we propose a WiFi vision-based system, 3D-ID, for person Re-ID in 3D space. Our system leverages the advances of WiFi and deep learning to help WiFi devices “see’’, identify, and recognize people. In particular, we leverage multiple antennas on next-generation WiFi devices and 2D AoA estimation of the signal reflections to enable WiFi to visualize a person in the physical environment. We then leverage deep learning to digitize the visualization of the person into 3D body representation and extract both the static body shape and dynamic walking patterns for person Re-ID. Our evaluation results under various indoor environments show that the 3D-ID system achieves an overall rank-1 accuracy of 85.3%. Results also show that our system is resistant to various attacks. The proposed 3D-ID is thus very promising as it could augment or complement camera-based systems.
Beyond The Gates: An Empirical Analysis of HTTP-Managed Password Stealers and Operators
Authors:
Athanasios Avgetidis, Omar Alrawi, Kevin Valakuzhy, and Charles Lever, Georgia Institute of Technology; Paul Burbage, MalBeacon; Angelos D. Keromytis, Fabian Monrose, and Manos Antonakakis, Georgia Institute of Technology
Abstract:
Password Stealers (Stealers) are commodity malware that specialize in credential theft. This work presents a large-scale longitudinal study of Stealers and their operators. Using a commercial dataset, we characterize the activity of over 4, 586 distinct Stealer operators through their devices spanning 10 different Stealer families. Operators make heavy use of proxies, including traditional VPNs, residential proxies, mobile proxies, and the Tor network when managing their botnet. Our affiliation analysis unveils a stratified enterprise of cybercriminals for each service offering and we identify privileged operators using graph analysis. We find several Stealer-as-a-Service providers that lower the economical and technical barrier for many cybercriminals. We estimate that service providers benefit from high-profit margins (up to 98%) and a lower-bound profit estimate of $11, 000 per month. We find high-profile targeting like the Social Security Administration, the U.S. House of Representatives, and the U.S. Senate. We share our findings with law enforcement and publish six months of the dataset, analysis artifact, and code.
Problematic Advertising and its Disparate Exposure on Facebook
Authors:
Muhammad Ali, Northeastern University; Angelica Goetzen, Max Planck Institute for Software Systems; Alan Mislove, Northeastern University; Elissa M. Redmiles, Max Planck Institute for Software Systems; Piotr Sapiezynski, Northeastern University
Abstract:
Targeted advertising remains an important part of the free web browsing experience, where advertisers’ targeting and personalization algorithms together find the most relevant audience for millions of ads every day. However, given the wide use of advertising, this also enables using ads as a vehicle for problematic content, such as scams or clickbait. Recent work that explores people’s sentiments toward online ads, and the impacts of these ads on people’s online experiences, has found evidence that online ads can indeed be problematic. Further, there is the potential for personalization to aid the delivery of such ads, even when the advertiser targets with low specificity. In this paper, we study Facebook — one of the internet’s largest ad platforms — and investigate key gaps in our understanding of problematic online advertising: (a) What categories of ads do people find problematic? (b) Are there disparities in the distribution of problematic ads to viewers? and if so, © Who is responsible — advertisers or advertising platforms? To answer these questions, we empirically measure a diverse sample of user experiences with Facebook ads via a 3-month longitudinal panel. We categorize over 32,000 ads collected from this panel (n=132); and survey participants’ sentiments toward their own ads to identify four categories of problematic ads. Statistically modeling the distribution of problematic ads across demographics, we find that older people and minority groups are especially likely to be shown such ads. Further, given that 22% of problematic ads had no specific targeting from advertisers, we infer that ad delivery algorithms (advertising platforms themselves) played a significant role in the biased distribution of these ads.
Bypassing Tunnels: Leaking VPN Client Traffic by Abusing Routing Tables
Authors:
Nian Xue, New York University; Yashaswi Malla, Zihang Xia, and Christina Pöpper, New York University Abu Dhabi; Mathy Vanhoef, imec-DistriNet, KU Leuven
The Impostor Among US(B): Off-Path Injection Attacks on USB Communications
Authors:
Robert Dumitru, The University of Adelaide and Defence Science and Technology Group; Daniel Genkin, Georgia Tech; Andrew Wabnitz, Defence Science and Technology Group; Yuval Yarom, The University of Adelaide
Abstract:
USB is the most prevalent peripheral interface in modern computer systems and its inherent insecurities make it an appealing attack vector. A well-known limitation of USB is that traffic is not encrypted. This allows on-path adversaries to trivially perform man-in-the-middle attacks. Off-path attacks that compromise the confidentiality of communications have also been shown to be possible. However, so far no off-path attacks that breach USB communications integrity have been demonstrated.
In this work we show that the integrity of USB communications is not guaranteed even against off-path attackers. Specifically, we design and build malicious devices that, even when placed outside of the path between a victim device and the host, can inject data to that path. Using our developed injectors we can falsify the provenance of data input as interpreted by a host computer system. By injecting on behalf of trusted victim devices we can circumvent any software-based authorisation policy defences that computer systems employ against common USB attacks. We demonstrate two concrete attacks. The first injects keystrokes allowing an attacker to execute commands. The second demonstrates file-contents replacement including during system install from a USB disk. We test the attacks on 29 USB 2.0 and USB 3.x hubs and find 14 of them to be vulnerable.
Cross Container Attacks: The Bewildered eBPF on Clouds
Authors:
Yi He and Roland Guo, Tsinghua University and BNRist; Yunlong Xing, George Mason University; Xijia Che, Tsinghua University and BNRist; Kun Sun, George Mason University; Zhuotao Liu, Ke Xu, and Qi Li, Tsinghua University
Abstract:
The extended Berkeley Packet Filter (eBPF) provides powerful and flexible kernel interfaces to extend the kernel functions for user space programs via running bytecode directly in the kernel space. It has been widely used by cloud services to enhance container security, network management, and system observability. However, we discover that the offensive eBPF that have been extensively discussed in Linux hosts can bring new attack surfaces to containers. With eBPF tracing features, attackers can break the container’s isolation and attack the host, e.g., steal sensitive data, DoS, and even escape the container. In this paper, we study the eBPF-based cross container attacks and reveal their security impacts in real world services. With eBPF attacks, we successfully compromise five online Jupyter/Interactive Shell services and the Cloud Shell of Google Cloud Platform. Furthermore, we find that the Kubernetes services offered by three leading cloud vendors can be exploited to launch cross-node attacks after the attackers escape the container via eBPF. Specifically, in Alibaba’s Kubernetes services, attackers can compromise the whole cluster by abusing their over-privileged cloud metrics or management Pods. Unfortunately, the eBPF attacks on containers are seldom known and can hardly be discovered by existing intrusion detection systems. Also, the existing eBPF permission model cannot confine the eBPF and ensure secure usage in shared-kernel container environments. To this end, we propose a new eBPF permission model to counter the eBPF attacks in containers.
Hiding in Plain Sight: An Empirical Study of Web Application Abuse in Malware
Authors:
Mingxuan Yao, Georgia Institute of Technology; Jonathan Fuller, United States Military Academy; Ranjita Pai Kasturi, Saumya Agarwal, Amit Kumar Sikder, and Brendan Saltaformaggio, Georgia Institute of Technology
Abstract:
Web applications provide a wide array of utilities that are abused by malware as a replacement for traditional attacker-controlled servers. Thwarting these Web App-Engaged (WAE) malware requires rapid collaboration between incident responders and web app providers. Unfortunately, our research found that delays in this collaboration allow WAE malware to thrive. We developed Marsea, an automated malware analysis pipeline that studies WAE malware and enables rapid remediation. Given 10K malware samples, Marsea revealed 893 WAE malware in 97 families abusing 29 web apps. Our research uncovered a 226% increase in the number of WAE malware since 2020 and that malware authors are beginning to reduce their reliance on attacker-controlled servers. In fact, we found a 13.7% decrease in WAE malware relying on attacker-controlled servers. To date, we have used Marsea to collaborate with the web app providers to take down 50% of the malicious web app content.
Device Tracking via Linux’s New TCP Source Port Selection Algorithm
Authors:
Moshe Kol, Amit Klein, and Yossi Gilad, Hebrew University of Jerusalem
Abstract:
We describe a tracking technique for Linux devices, exploiting a new TCP source port generation mechanism recently introduced to the Linux kernel. This mechanism is based on an algorithm, standardized in RFC 6056, for boosting security by better randomizing port selection. Our technique detects collisions in a hash function used in the said algorithm, based on sampling TCP source ports generated in an attacker-prescribed manner. These hash collisions depend solely on a per-device key, and thus the set of collisions forms a device ID that allows tracking devices across browsers, browser privacy modes, containers, and IPv4/IPv6 networks (including some VPNs). It can distinguish among devices with identical hardware and software, and lasts until the device restarts.
We implemented this technique and then tested it using tracking servers in two different locations and with Linux devices on various networks. We also tested it on an Android device that we patched to introduce the new port selection algorithm. The tracking technique works in real-life conditions, and we report detailed findings about it, including its dwell time, scalability, and success rate in different network types. We worked with the Linux kernel team to mitigate the exploit, resulting in a security patch introduced in May 2022 to the Linux kernel, and we provide recommendations for better securing the port selection algorithm in the paper.
Glowing in the Dark: Uncovering IPv6 Address Discovery and Scanning Strategies in the Wild
Authors:
Hammas Bin Tanveer, The University of Iowa; Rachee Singh, Microsoft and Cornell University; Paul Pearce, Georgia Tech; Rishab Nithyanand, University of Iowa
Abstract:
In this work we identify scanning strategies of IPv6 scanners on the Internet. We offer a unique perspective on the behavior of IPv6 scanners by conducting controlled experiments leveraging a large and unused /56 IPv6 subnet. We selectively make parts of the subnet visible to scanners by hosting applications that make direct or indirect contact with IPv6- capable servers on the Internet. By careful experiment design, we mitigate the effects of hidden variables on scans sent to our /56 subnet and establish causal relationships between IPv6 host activity types and the scanner attention they evoke. We show that IPv6 host activities e.g., Web browsing, membership in the NTP pool and Tor network, cause scanners to send a magnitude higher number of unsolicited IP scans and reverse DNS queries to our subnet than before. DNS scanners focus their scans in narrow regions of the address space where our applications are hosted whereas IP scanners broadly scan the entire subnet. Even after the host activity from our subnet subsides, we observe persistent residual scanning to portions of the address space that previously hosted applications.
Hot Pixels: Frequency, Power, and Temperature Attacks on GPUs and Arm SoCs
Authors:
Hritvik Taneja, Jason Kim, and Jie Jeff Xu, Georgia Tech; Stephan van Schaik, University of Michigan; Daniel Genkin, Georgia Tech; Yuval Yarom, Ruhr University Bochum
Abstract:
The drive to create thinner, lighter, and more energy efficient devices has resulted in modern SoCs being forced to balance a delicate tradeoff between power consumption, heat dissipation, and execution speed (i.e., frequency). While beneficial, these DVFS mechanisms have also resulted in software-visible hybrid side-channels, which use software to probe analog properties of computing devices. Such hybrid attacks are an emerging threat that can bypass countermeasures for traditional microarchitectural side-channel attacks.
Given the rise in popularity of both Arm SoCs and GPUs, in this paper we investigate the susceptibility of these devices to information leakage via power, temperature and frequency, as measured via internal sensors. We demonstrate that the sensor data observed correlates with both instructions executed and data processed, allowing us to mount software-visible hybrid side-channel attacks on these devices.
To demonstrate the real-world impact of this issue, we present JavaScript-based pixel stealing and history sniffing attacks on Chrome and Safari, with all side channel countermeasures enabled. Finally, we also show website fingerprinting attacks, without any elevated privileges.
TAP: Transparent and Privacy-Preserving Data Services
Authors:
Daniel Reijsbergen and Aung Maw, Singapore University of Technology and Design; Zheng Yang, Southwest University; Tien Tuan Anh Dinh and Jianying Zhou, Singapore University of Technology and Design
Abstract:
Users today expect more security from services that handle their data. In addition to traditional data privacy and integrity requirements, they expect transparency, i.e., that the service’s processing of the data is verifiable by users and trusted auditors. Our goal is to build a multi-user system that provides data privacy, integrity, and transparency for a large number of operations, while achieving practical performance.
To this end, we first identify the limitations of existing approaches that use authenticated data structures. We find that they fall into two categories: 1) those that hide each user’s data from other users, but have a limited range of verifiable operations (e.g., CONIKS, Merkle2, and Proofs of Liabilities), and 2) those that support a wide range of verifiable operations, but make all data publicly visible (e.g., IntegriDB and FalconDB). We then present TAP to address the above limitations. The key component of TAP is a novel tree data structure that supports efficient result verification, and relies on independent audits that use zero-knowledge range proofs to show that the tree is constructed correctly without revealing user data. TAP supports a broad range of verifiable operations, including quantiles and sample standard deviations. We conduct a comprehensive evaluation of TAP, and compare it against two state-of-the-art baselines, namely IntegriDB and Merkle2, showing that the system is practical at scale.
V1SCAN: Discovering 1-day Vulnerabilities in Reused C/C++ Open-source Software Components Using Code Classification Techniques
Authors:
Seunghoon Woo, Eunjin Choi, Heejo Lee, and Hakjoo Oh, Korea University
Abstract:
We present V1SCAN, an effective approach for discovering 1-day vulnerabilities in reused C/C++ open-source software (OSS) components. Reusing third-party OSS has many benefits, but can put the entire software at risk owing to the vulnerabilities they propagate. In mitigation, several techniques for detecting propagated vulnerabilities, which can be classified into version- and code-based approaches, have been proposed. However, state-of-the-art techniques unfortunately produce many false positives or negatives when OSS projects are reused with code modifications.
In this paper, we show that these limitations can be addressed by improving version- and code-based approaches and synergistically combining them. By classifying reused code from OSS components, V1SCAN only considers vulnerabilities contained in the target program and filters out unused vulnerable code, thereby reducing false alarms produced by version-based approaches. V1SCAN improves the coverage of code-based approaches by classifying vulnerable code and then detecting vulnerabilities propagated with code changes in various code locations. Evaluation on GitHub popular C/C++ software showed that V1SCAN outperformed state-of-the-art vulnerability detection approaches by discovering 50% more vulnerabilities than they detected. In addition, V1SCAN reduced the false positive rate of the simple integration of existing version- and code-based approaches from 71% to 4% and the false negative rate from 33% to 7%. With V1SCAN, developers can detect propagated vulnerabilities with high accuracy, maintaining a secure software supply chain.
One Size Does Not Fit All: Uncovering and Exploiting Cross Platform Discrepant APIs in WeChat
Authors:
Chao Wang, Yue Zhang, and Zhiqiang Lin, The Ohio State University
Abstract:
The past few years have witnessed a boom of mobile super apps, which are the apps offering multiple services such as e-commerce, e-learning, and e-government via miniapps executed inside. While originally designed for mobile platforms, super apps such as WeChat have also been made available on desktop platforms such as Windows. However, when running on desktop platforms, WeChat experiences differences in some behaviors, which presents opportunities for attacks (e.g., platform fingerprinting attacks). This paper thus aims to systematically identify the potential discrepancies in the APIs of WeChat across platforms and demonstrate how these differences can be exploited by remote attackers or local malicious miniapps. To this end, we present APIDIFF, an automatic tool that generates test cases for each API and identifies execution discrepancies. With APIDIFF, we have identified three sets of discrepant APIs that exhibit existence (109), permission (17), and output (22) discrepancies across platforms and devices, and provided concrete examples of their exploitation. We have responsibly disclosed these vulnerabilities to Tencent and received bug bounties for our findings. These vulnerabilities were ranked as high-severity and some have already been patched.
Reversing, Breaking, and Fixing the French Legislative Election E-Voting Protocol
Authors:
Alexandre Debant and Lucca Hirschi, Université de Lorraine, Inria, CNRS, France
Abstract:
We conduct a security analysis of the e-voting protocol used for the largest political election using e-voting in the world, the 2022 French legislative election for the citizens overseas. Due to a lack of system and threat model specifications, we built and contributed such specifications by studying the French legal framework and by reverse-engineering the code base accessible to the voters. Our analysis reveals that this protocol is affected by two design-level and implementation-level vulnerabilities. We show how those allow a standard voting server attacker and even more so a channel attacker to defeat the election integrity and ballot privacy due to 5 attack variants. We propose and discuss 5 fixes to prevent those attacks. Our specifications, the attacks, and the fixes were acknowledged by the relevant stakeholders during our responsible disclosure. They implemented our fixes to prevent our attacks for future elections. Beyond this protocol, we draw general lessons, recommendations, and open questions from this instructive experience where an e-voting protocol meets the real-world constraints of a large-scale, political election.
Access Denied: Assessing Physical Risks to Internet Access Networks
Authors:
Alexander Marder, CAIDA / UC San Diego; Zesen Zhang, UC San Diego; Ricky Mok and Ramakrishna Padmanabhan, CAIDA / UC San Diego; Bradley Huffaker, CAIDA/ UC San Diego; Matthew Luckie, University of Waikato; Alberto Dainotti, Georgia Tech; kc claffy, CAIDA/ UC San Diego; Alex C. Snoeren and Aaron Schulman, UC San Diego
Abstract:
Regional access networks play an essential role in connecting both wireline and mobile users to the Internet. Today’s access networks support 5G cellular phones, cloud services, hospital and financial services, and remote work essential to the modern economy. Yet long-standing economic and architectural constraints produce points of limited redundancy that leave these networks exposed to targeted physical attacks resulting in widespread outages. This risk was dramatically shown in December 2020, when a bomb destroyed part of AT&T’s regional access network in Nashville, Tennessee disabling 911 emergency dispatch, air traffic control, hospital networks, and credit card processing, among other services.
We combine new techniques for analyzing access-network infrastructure deployments with measurements of large-scale outages to demonstrate the feasibility and quantify potential impacts of targeted attacks. Our study yields insights into physical attack surfaces and resiliency limits of regional access networks. We analyze potential approaches to mitigate the risks we identify and discuss drawbacks identified by network operators. We hope that our empirical evaluation will inform risk assessments and operational practices, as well as motivate further analyses of this critical infrastructure.
Jinn: Hijacking Safe Programs with Trojans
Authors:
Komail Dharsee and John Criswell, University of Rochester
Abstract:
Untrusted hardware supply chains enable malicious, powerful, and permanent alterations to processors known as hardware trojans. Such hardware trojans can undermine any software-enforced security policies deployed on top of the hardware. Existing defenses target a select set of hardware components, specifically those that implement hardware-enforced security mechanisms such as cryptographic cores, user/kernel privilege isolation, and memory protections.
We observe that computing systems exercise general purpose processor logic to implement software-enforced security policies. This makes general purpose logic security critical since tampering with it could violate software-based security policies. Leveraging this insight, we develop a novel class of hardware trojans, which we dub Jinn trojans, that corrupt general-purpose hardware to enable flexible and powerful high level attacks. Jinn trojans deactivate compiler-based security-enforcement mechanisms, making type-safe software vulnerable to memory-safety attacks. We prototyped design-time Jinn trojans in the gem5 simulator and used them to attack programs written in Rust, inducing memory-safety vulnerabilities to launch control-flow hijacking attacks. We find that Jinn trojans can effectively compromise software-enforced security policies by compromising a single bit of architectural state with as little as 8 bits of persistent trojan-internal state. Thus, we show that Jinn trojans are effective even when planted in general purpose hardware, disjoint from any hardware-enforced security components. We show that protecting hardware-enforced security logic is insufficient to keep a system secure from hardware trojans.
Checking Passwords on Leaky Computers: A Side Channel Analysis of Chrome’s Password Leak Detect Protocol
Authors:
Andrew Kwong, UNC Chapel Hill; Walter Wang, University of Michigan; Jason Kim, Georgia Tech; Jonathan Berger, Bar Ilan University; Daniel Genkin, Georgia Tech; Eyal Ronen, Tel Aviv University; Hovav Shacham, UT Austin; Riad Wahby, CMU; Yuval Yarom, Ruhr University Bochum
Abstract:
The scale and frequency of password database compromises has led to widespread and persistent credential stuffing attacks, in which attackers attempt to use credentials leaked from one service to compromise accounts with other services. In response, browser vendors have integrated password leakage detection tools, which automatically check the user’s credentials against a list of compromised accounts upon each login, warning the user to change their password if a match is found. In particular, Google Chrome uses a centralized leakage detection service designed by Thomas et al. (USENIX Security ’19) that aims to both preserve the user’s privacy and hide the server’s list of compromised credentials.
In this paper, we show that Chrome’s implementation of this protocol is vulnerable to several microarchitectural side-channel attacks that violate its security properties. Specifically, we demonstrate attacks against Chrome’s use of the memory-hard hash function scrypt, its hash-to-elliptic curve function, and its modular inversion algorithm. While prior work discussed the theoretical possibility of side-channel attacks on scrypt, we develop new techniques that enable this attack in practice, allowing an attacker to recover the user’s password with a single guess when using a dictionary attack. For modular inversion, we present a novel cryptanalysis of the Binary Extended Euclidian Algorithm (BEEA) that extracts its inputs given a single, noisy trace, thereby allowing a malicious server to learn information about a client’s password.
Title Redacted Due to Vulnerability Embargo
This paper, title, and abstract are under embargo and will be released to the public on the first day of the symposium, Wednesday, August 9, 2023.
Authors:
Daniel Moghimi, UCSD
UnGANable: Defending Against GAN-based Face Manipulation
Authors:
Zheng Li, CISPA Helmholtz Center for Information Security; Ning Yu, Salesforce Research; Ahmed Salem, Microsoft Research; Michael Backes, Mario Fritz, and Yang Zhang, CISPA Helmholtz Center for Information Security
Abstract:
Deepfakes pose severe threats of visual misinformation to our society. One representative deepfake application is face manipulation that modifies a victim’s facial attributes in an image, e.g., changing her age or hair color. The state-of-the-art face manipulation techniques rely on Generative Adversarial Networks (GANs). In this paper, we propose the first defense system, namely UnGANable, against GAN-inversion-based face manipulation. In specific, UnGANable focuses on defending GAN inversion, an essential step for face manipulation. Its core technique is to search for alternative images (called cloaked images) around the original images (called target images) in image space. When posted online, these cloaked images can jeopardize the GAN inversion process. We consider two state-of-the-art inversion techniques including optimization-based inversion and hybrid inversion, and design five different defenses under five scenarios depending on the defender’s background knowledge. Extensive experiments on four popular GAN models trained on two benchmark face datasets show that UnGANable achieves remarkable effectiveness and utility performance, and outperforms multiple baseline methods. We further investigate four adaptive adversaries to bypass UnGANable and show that some of them are slightly effective.
Decompiling x86 Deep Neural Network Executables
Authors:
Zhibo Liu, Yuanyuan Yuan, and Shuai Wang, The Hong Kong University of Science and Technology; Xiaofei Xie, Singapore Management University; Lei Ma, University of Alberta
Abstract:
Due to their widespread use on heterogeneous hardware devices, deep learning (DL) models are compiled into executables by DL compilers to fully leverage low-level hardware primitives. This approach allows DL computations to be undertaken at low cost across a variety of computing platforms, including CPUs, GPUs, and various hardware accelerators.
We present BTD (Bin to DNN), a decompiler for deep neural network (DNN) executables. BTD takes DNN executables and outputs full model specifications, including types of DNN operators, network topology, dimensions, and parameters that are (nearly) identical to those of the input models. BTD delivers a practical framework to process DNN executables compiled by different DL compilers and with full optimizations enabled on x86 platforms. It employs learning-based techniques to infer DNN operators, dynamic analysis to reveal network architectures, and symbolic execution to facilitate inferring dimensions and parameters of DNN operators.
Our evaluation reveals that BTD enables accurate recovery of full specifications of complex DNNs with millions of parameters (e.g., ResNet). The recovered DNN specifications can be re-compiled into a new DNN executable exhibiting identical behavior to the input executable. We show that BTD can boost two representative attacks, adversarial example generation and knowledge stealing, against DNN executables. We also demonstrate cross-architecture legacy code reuse using BTD, and envision BTD being used for other critical downstream tasks like DNN security hardening and patching.
All cops are broadcasting: TETRA under scrutiny
Authors:
Carlo Meijer, Wouter Bokslag, and Jos Wetzels, Midnight Blue
Abstract:
This paper presents the first public in-depth security analysis of TETRA (Terrestrial Trunked Radio): a European standard for trunked radio globally used by government agencies, police, prisons, emergency services and military operators. Additionally, it is widely deployed in industrial environments such as factory campuses, harbor container terminals and airports, as well as critical infrastructure such as SCADA telecontrol of oil rigs, pipelines, transportation and electric and water utilities. Authentication and encryption within TETRA are handled by secret, proprietary cryptographic cipher-suites. This secrecy thwarts public security assessments and independent academic scrutiny of the protection that TETRA claims to provide.
The widespread adoption of TETRA, combined with the often sensitive nature of the communications, raises legitimate questions regarding its cryptographic resilience. In this light, we have set out to achieve two main goals. First, we demonstrate the feasibility of obtaining the underlying secret cryptographic primitives through reverse engineering. Second, we provide an initial assessment of the robustness of said primitives in the context of the protocols in which they are used.
We present five serious security vulnerabilities pertaining to TETRA, two of which are deemed critical. Furthermore, we present descriptions and implementations of the primitives, enabling further academic scrutiny. Our findings have been validated in practice using a common-off-the-shelf radio on a TETRA network lab setup.
More than a year ago, we started to communicate our preliminary findings through a coordinated disclosure process with several key stakeholders. During this process we have actively supported these stakeholders in the identification, development and deployment of possible mitigations.

